好きな声で好きなセリフを喋らせられるローカルAI「Irodori-TTS」の使い方、日本語特化でローカル動作するので無制限に生成し放題


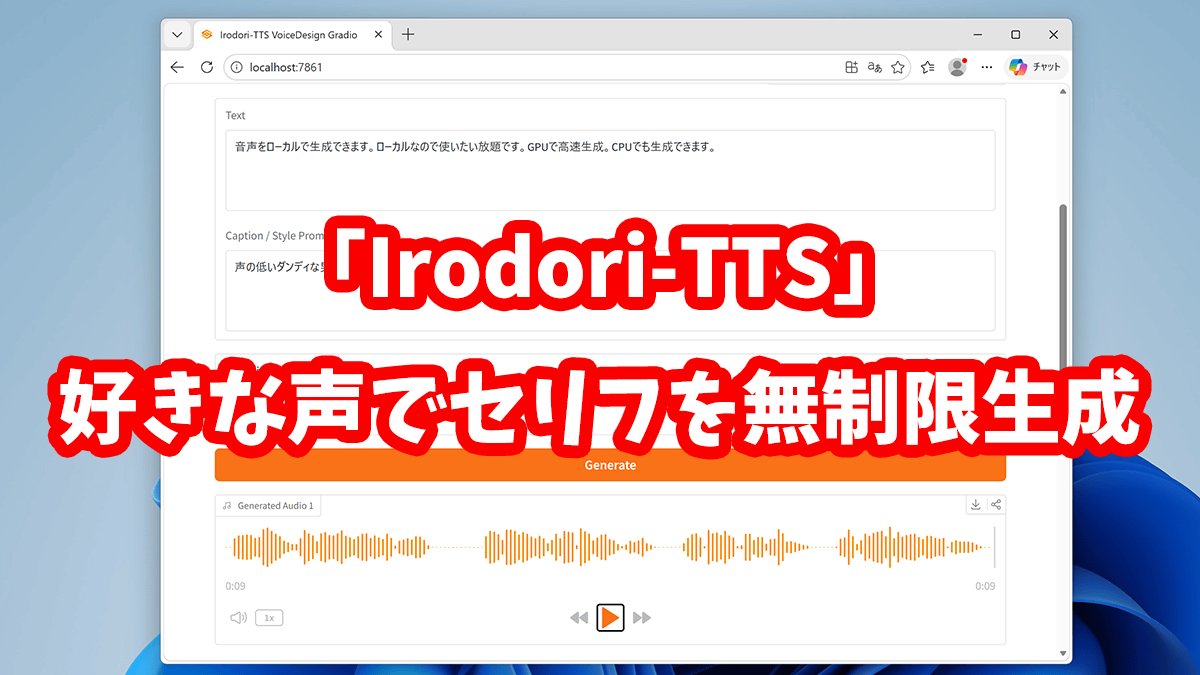
「Irodori-TTS」はAratako氏が開発した日本語特化の音声合成AIモデル(TTSモデル)です。ローカルで動作する軽量モデルで、「セリフ」「声」「感情」を自由に指定して音声を生成することができます。NVIDIA製GPUを搭載したPCなら数秒で生成可能で、GPU非搭載PCでもCPUを使って生成できます。かなり高品質なセリフ音声を作れて便利なので、インストール手順や使い方をまとめてみました。
https://github.com/Aratako/Irodori-TTS
Aratako/Irodori-TTS-500M-v2 · Hugging Face
https://huggingface.co/Aratako/Irodori-TTS-500M-v2
・目次
◆1:Irodori-TTSのインストール
◆2:Irodori-TTSで音声生成【起動&最初の生成】
◆3:Irodori-TTSで音声生成【リファレンス音声を使って声を指定】
◆4:Irodori-TTSで音声生成【絵文字で感情を指定】
◆5:Irodori-TTSで音声生成【説明文で声を指定】
◆1:Irodori-TTSのインストール
Irodori-TTSをインストールする前に、プログラミング言語の「Python」、Python用パッケージ管理ツールの「uv」、バージョン管理システムの「Git」をインストールしておく必要があります。Pythonは公式サイトからダウンロードしてインストール可能。GitとuvはWindows標準コマンドの「winget」を使ってインストールできます。
wingetでGitとuvをインストールする手順は次の通り。まず、スタートメニューからターミナルを探して起動します。

「winget install --id Git.Git -e」と入力してEnterキーを押します。

Gitのインストールが自動的に進むのでしばらく待ちます。

「インストールが完了しました」と表示されればOK。

続いて「winget install --id=astral-sh.uv -e」と入力してEnter。

「インストールが完了しました」と表示されれば必要なソフトウェアの準備は完了。×ボタンをクリックしてターミナルを閉じます。

次に、Irodori-TTSをインストールするフォルダを作ります。今回はCドライブの直下に「ai」というフォルダを作成しました。

作成したフォルダを開いて、何もない部分を右クリックして「ターミナルで開く」をクリック。
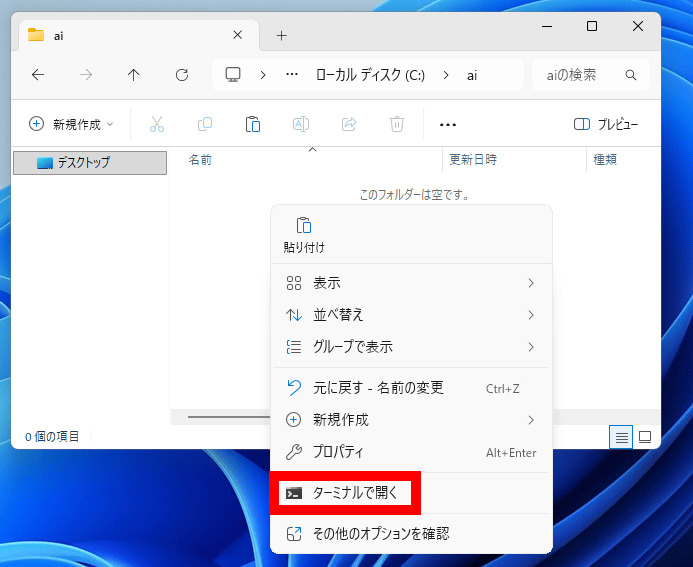
ターミナルが起動したら「git clone https://github.com/Aratako/Irodori-TTS.git」と入力してEnter。

「cd Irodori-TTS」と入力してEnter。
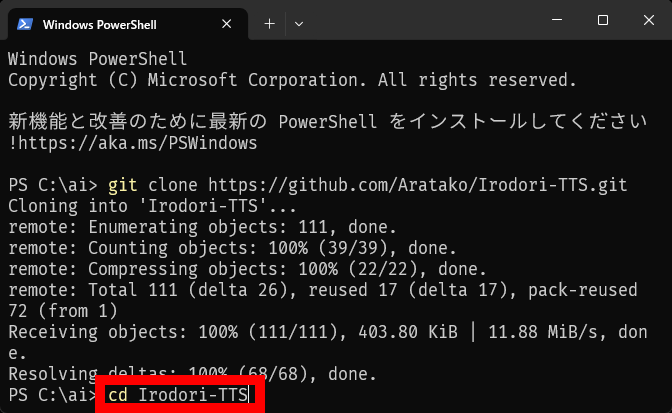
「uv sync」と入力してEnter。

必要なパッケージのインストールが始まるのでしばらく待ちます。

最下部に「C:\ai\Irodori-TTS」と表示されればIrodori-TTSのインストールは完了です。

◆2:Irodori-TTSで音声生成【起動&最初の生成】
Irodori-TTSを使うには、まずターミナルを起動して「cd C:\ai\Irodori-TTS」と入力してEnter。

続いて「uv run python gradio_app.py --server-name 0.0.0.0 --server-port 7860」と入力してEnter。

「Running on local URL: http://0.0.0.0:7860」と表示されたらOK。

EdgeやFirefoxなどのブラウザを起動して「http://localhost:7860」にアクセスします。

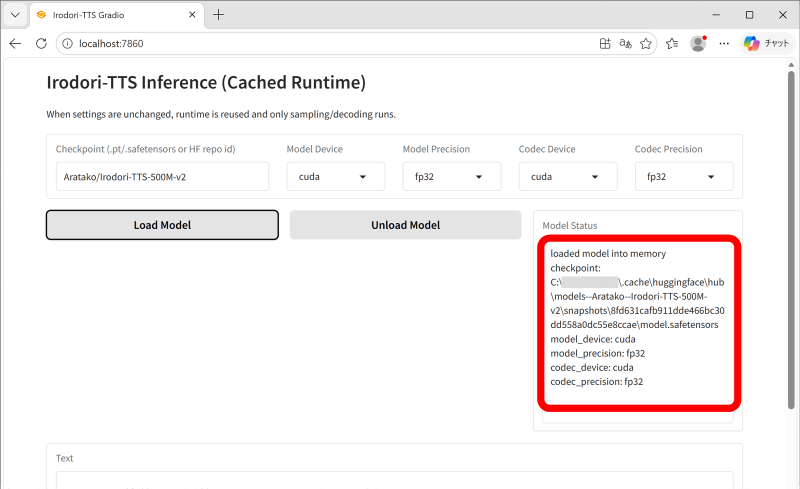
これがIrodori-TTSのウェブUIです。TTSモデルを読み込むために「Load Model」をクリックします。

「loaded model into memory」と表示されたらモデルの読み込みは完了。初回はモデルのダウンロードが必要なため時間がかかりますが、2回目以降はローカルに保存済みのモデルを使うので素早く読み込めます。なお、記事作成時点では2026年3月に公開された「Irodori-TTS-500M-v2」を使う仕組みになっています。
「Text」の欄にセリフを入力して「Generate」をクリック。

生成が完了したら「Generate」の下部に音声再生画面が表示されます。再生ボタンをクリックすると再生可能。右上のダウンロードボタンをクリックするとダウンロードできます。

実際にセリフを生成する様子を録画してみました。かなり高品質な音声を生成できることが分かります。
ローカル音声合成AI「Irodori-TTS」でセリフを生成 - YouTube
Irodori-TTSはCUDAを用いてGPU処理できるほか、CPUでも処理できます。NVIDIA GeForce RTX 5070 TiとAMD Ryzen 7 9700Xを搭載したPCの場合、5秒の動画をGPUで生成すると約3秒、CPUで生成すると約90秒で出力できました。
なお、生成した音声はダウンロードボタンで保存できるほか、「C:\ai\Irodori-TTS\gradio_outputs\」にも自動保存されます。

◆3:Irodori-TTSで音声生成【リファレンス音声を使って声を指定】
Irodori-TTSではリファンレンス音声を指定することで「リファンレンスと同じ声の音声」を生成することができます。リファンレンス音声を指定するには、音声ファイルを「Reference Audio Upload」の欄にドラッグ&ドロップすればOK。

同じセリフを「女性の高い声」と「おじいさんの声」で生成してみました。リファンレンス音声を再現しつつ指定通りのセリフを生成できています。
ローカル音声合成AI「Irodori-TTS」でセリフを生成【リファレンス音声で声色を指定】 - YouTube
◆4:Irodori-TTSで音声生成【絵文字で感情を指定】
セリフのテキストに絵文字を混ぜることで感情を指定することもできます。使用可能な絵文字は以下の通り。コピペできるようにどこかに保存しておくと便利です。
絵文字感情・スタイル👂囁き、耳元の音😮💨吐息、溜息、寝息⏸️間、沈黙🤭笑い(くすくす、含み笑いなど)🥵喘ぎ、うめき声、唸り声📢エコー、リバーブ😏からかうように、甘えるように🥺声を震わせながら、自信のなさげに🌬️息切れ、荒い息遣い、呼吸音😮息をのむ👅舐める音、咀嚼音、水音💋リップノイズ🫶優しく😭嗚咽、泣き声、悲しみ😱悲鳴、叫び、絶叫😪眠そうに、気だるげに⏩早口、一気にまくしたてる、急いで📞電話越し、スピーカー越しのような音🐢ゆっくりと🥤唾を飲み込む音🤧咳き込み、鼻をすする、くしゃみ、咳払い😒舌打ち😰慌てて、動揺、緊張、どもり😆喜びながら😠怒り、不満げに、拗ねながら😲驚き、感嘆🥱あくび😖苦しげに😟心配そうに🫣恥ずかしそうに、照れながら🙄呆れたように😊楽しげに、嬉しそうに👌相槌、頷く音🙏懇願するように🥴酔っ払って🎵鼻歌🤐口を塞がれて😌安堵、満足げに🤔疑問の声
同じセリフに異なる絵文字を加えて感情をコントロールしてみました。泣いたり怒ったりといった基本的な感情のほかに「電話越し」「喘ぎ」「鼻歌」「舌打ち」など多様な表現に対応しています。
ローカル音声合成AI「Irodori-TTS」でセリフを生成【絵文字で感情を指定】 - YouTube
◆5:Irodori-TTSで音声生成【説明文で声を指定】
リファンレンス音声ではなく説明文で声を指定するVoiceDesign版も用意されています。Irodori-TTSのVoiceDesign版を実行するには以下のコマンドを1行ずつ実行して「http://localhost:7861」にアクセスします。
cd C:\ai\Irodori-TTS
uv run python gradio_app_voicedesign.py --server-name 0.0.0.0 --server-port 7861
「Text」欄にセリフ、「Caption」欄に声の説明を入力して「Generate」をクリックすると音声を生成できます。

同じセリフを異なる声で生成してみました。性別や年齢、エコーの有無などを指示通りに再現することができました。
ローカル音声合成AI「Irodori-TTS」でセリフを生成【説明文で声色を指定】 - YouTube
Irodori-TTSはウェブUIだけでなくコマンド経由でも実行可能。詳しい仕様は以下のページにまとまっています。
GitHub - Aratako/Irodori-TTS: A Flow Matching-based Text-to-Speech Model with Emoji-driven Style Control · GitHub
https://github.com/Aratako/Irodori-TTS
