1100万時間の動画で学習したPC操作AI「FDM-1」が登場、動画の学習方法を根本から見直して2時間の動画を100万トークンに圧縮可能&自動運転車にも応用できる


サンフランシスコに拠点を置くStandard IntelligenceがAIモデル「FDM-1」を発表しました。FDM-1は1100万時間に及ぶ動画を学習しており、「世界初の汎用的なコンピューターアクションモデル」としてアピールされています。
The First Fully General Computer Action Model | blog
https://si.inc/posts/fdm1/
PCを操作可能なAIは既に製品化されていますが、ほとんどのAIは「PCのスクリーンショットをベースに開発された視覚言語モデル(VLM)に強化学習を施す」という手法で作られており、CADアプリの操作などの長時間にわたるタスクが苦手です。また、VLMの開発時にはスクリーンショットに適切な説明を付与する作業(アノテーション)が必要であり、アノテーションのために大量の人間と多くの時間を要することになります。
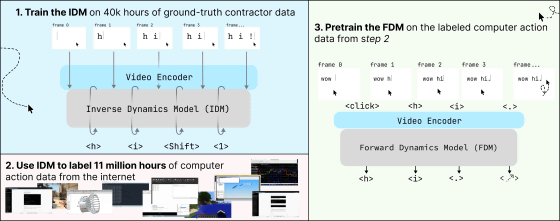
実写動画のアノテーションを自動実行するのは難しいですが、PCを操作する動画の場合は「画面に『h』と表示されたということは『hキーを押した』ということだ」と言ったように画面上の変化と操作内容を1対1で紐付けられるため、比較的容易に自動アノテーションシステムを構築できます。FDM-1を開発する際は、最初に4万時間分の動画を業者に委託して人力でアノテーションし、そのデータからIDMを開発して1100万時間の動画を自動アノテーションしました。

さらに、PC操作特有の状況に合わせたエンコーダーも開発。これらの工夫によって、FDM-1では3万6000フレームの動画を20万トークンで表現できるという高効率性を確保することに成功しました。同じ20万トークンだとGeminiでは775フレーム、Claudeでは162フレームしか扱うことができません。開発チームは「約2時間の30fps動画を100万トークンに圧縮可能」と述べ、FDM-1の効率の高さをアピールしています。

少ないトークンで長い動画を扱えるようになったことで、FDM-1はCGアプリやCADアプリなどの長時間の前後関係が重要なアプリケーションも自動実行できるようになりました。

また、車の操作を矢印キーでの操作に置き換えることで、FDM-1を自動運転システムに転用することもできます。

Standard Intelligenceは「FDM-1によって、PC操作AIは『学習データに制約される状態』から『計算量に制約される状態』に移行することができる」と述べ、成果をアピールしています。
