1万種類を超える大規模言語モデル(LLM)をまとめてダウンロード数や類似性などを分かりやすく視覚化したデータライブラリが公開される


2022年後半から「ChatGPT」や「Bard」など数え切れないほどの大規模言語モデル(LLM)およびAIサービスが登場し、世界中のユーザーが生成AIを積極的に使い始めるようになりました。こうした大規模言語モデルの多くは機械学習モデルとデータセットのリポジトリであるHugging Faceに寄託されていますが、スタンフォード大学の研究者らがHugging Faceのデータをまとめて視覚化したものを新たに公開しました。
https://doi.org/10.48550/arXiv.2307.09793
Constellation
https://constellation.sites.stanford.edu/
上記の「Constellation」にアクセスし、「Access Constellation」をクリックします。

次に表示したいLLMを指定します。上の数値は最小ダウンロード数で、指定した数字を超えてHugging Faceからダウンロードされたもののみを表示したいときに変更します。これにより、人気のあるLLMだけを絞り込むことができます。下の数値はクラスター数といい、簡単に言うとLLMを何個のグループに分けるのかを指定するものです。LLMは似たもの同士でグループ分けされます。

今回はワードクラウドを表示するチェックボックスにチェックを入れ、「Run Clustering」をクリック。しばらく待つといくつかのグラフが表示されます。

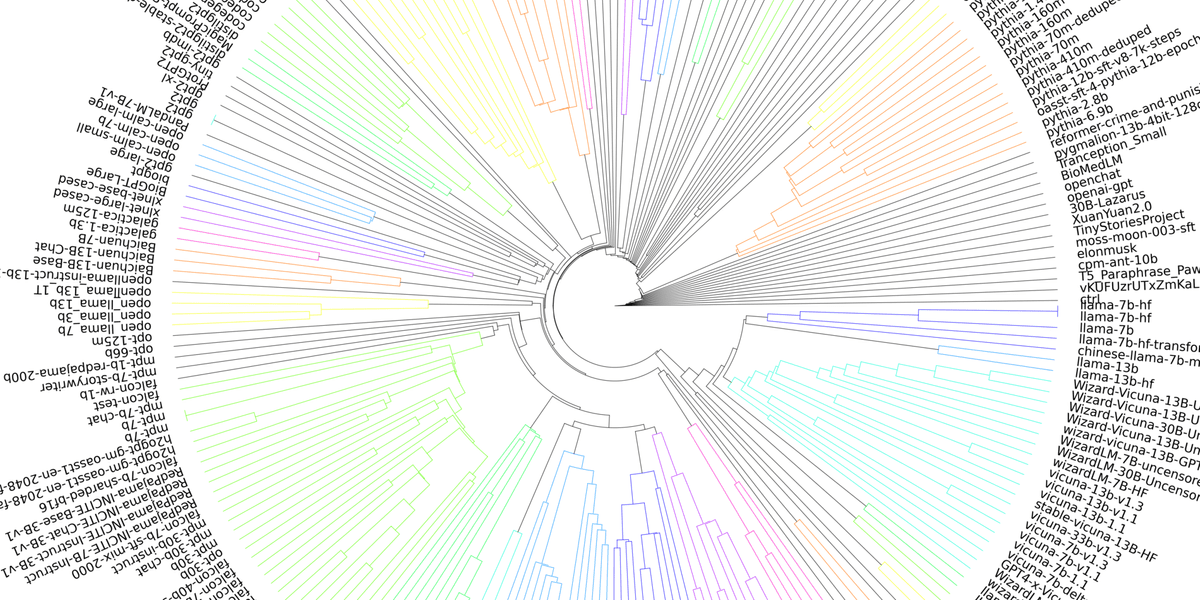
まず一つ目に表示されるのは、今回の指定によりフィルタリングされた全LLMを体系化した樹形図です。非常に見にくいですが、ズームなどを駆使すれば拡大して表示することができます。

ChatGPTやGoogleのBardに匹敵する精度のLLM「Vicuna-13B」は一体何から派生したのか、類似する言語モデルは何かなどを確認できます。

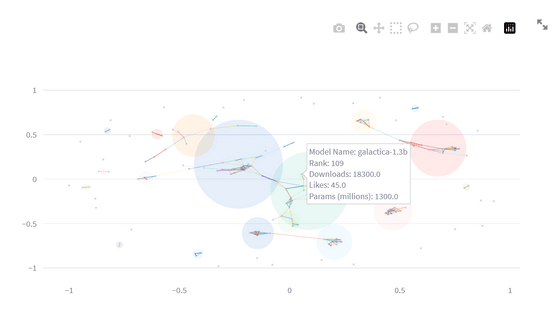
これは、ルーヴァン法を用いて各LLMをいくつかのコミュニティに分けたときのグラフです。深いつながりのあるLLM同士は一つのコミュニティと見なされ、薄い円で囲われています。各ノード(LLM)にカーソルを合わせると、LLMの名前、ダウンロード数ランキングの順位、ダウンロード数、Hugging Faceで行われた「いいね」数、パラメーター数が表示されます。
次に表示されるのは、各LLMとのつながりが多いLLMの上位20件をまとめたリストです。オープンソースで商用利用が可能な「Falcon」のモデルが、上位3件を占めています。

続いては、コミュニティの規模を基に並べられたLLMのリストが表示されます。最も規模が大きいのはfalcon-7b-instruct。次に大きいのが、「GPT-3」に近い性能の言語モデルをオープンソースで目指す「GPT-Neo」のモデルのひとつであるgpt-neo-125mです。

各クラスターごとに、どんなモデル群が突出しているのかが分かるワードクラウドも表示されます。

最後に表示されるのは、ダウンロード数といいね数を示し合わせたグラフです。1360万件という異様なダウンロード数を誇っていたのはOpenAIのオープンソースLLM「GPT-2」でした。

世にあふれるLLMには「GPT」や「model」など似たような名前が付けられることが多いです。今回のデータライブラリを作成した研究者らは、LLMの名前にどんな単語がどれくらい登場しているのかを細かくリスト化し、ジャーナルに記載しています。

