gpt-oss-20bより高性能な中国製AI「GLM-4.7-Flash」が登場


中国に拠点を置くAI企業のZ.aiがローカルで動作する軽量AIモデル「GLM-4.7-Flash」を2026年1月19日に公開しました。GLM-4.7-Flashは多くのベンチマークテストでOpenAIの「gpt-oss-20b」を上回る性能を示しています。
Introducing GLM-4.7-Flash: Your local coding and agentic assistant.
Setting a new standard for the 30B class, GLM-4.7-Flash balances high performance with efficiency, making it the perfect lightweight deployment option. Beyond coding, it is also recommended for creative writing,… pic.twitter.com/gd7hWQathC— Z.ai (@Zai_org) January 19, 2026
GLM-4.7-Flashは複数の専門モデルを組み合わせるMoEアーキテクチャを採用したAIモデルで、総パラメーター数は300億、アクティブパラメーター数は30億です。
GLM-4.7-Flash is a 30B-A3B MoE model.— Z.ai (@Zai_org) January 19, 2026
「GLM-4.7-Flash(総パラメーター数:300億、アクティブパラメーター数30億)」「Qwen3-30B-A3B-Thinking-2507(総パラメーター数:300億、アクティブパラメーター数30億)」「gpt-oss-20b(総パラメーター数:210億、アクティブパラメーター数36億)」の各種ベンチマーク結果が以下。ほとんどのテストでGLM-4.7-Flashが最も高いスコアを記録しています。

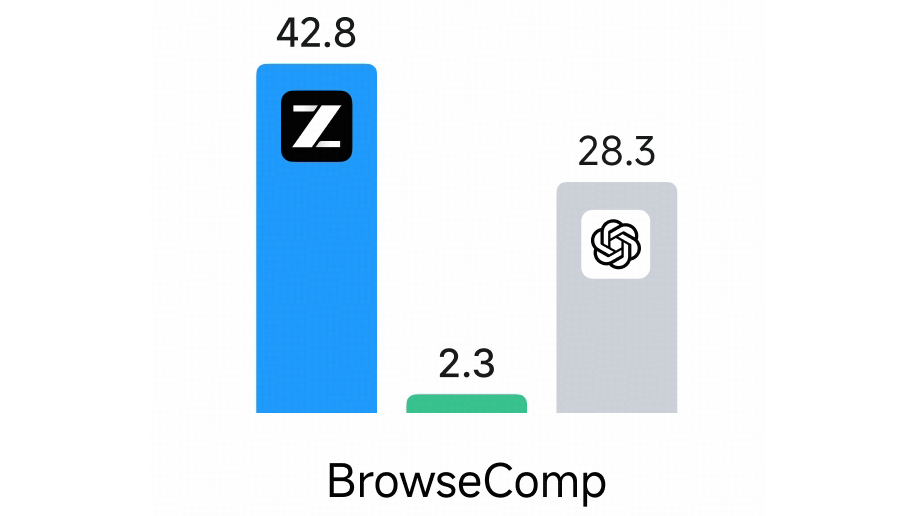
なお、上記のグラフのうちウェブ検索能力を測定するBrowseCompのグラフに誤りがあったとのこと。正しいグラフは以下で、GLM-4.7-FlashがQwen3-30B-A3B-Thinking-2507やgpt-oss-20bに大差をつけています。

GLM-4.7-Flashはオープンモデルとして開発されており、以下のリンク先でモデルデータをダウンロードできます。ライセンスはMIT Licenseです。
zai-org/GLM-4.7-Flash · Hugging Face
https://huggingface.co/zai-org/GLM-4.7-Flash
Z.aiが公開しているBF16版GLM-4.7-Flashを動作させるには45GB以上のVRAMが必要です。Z.aiは「GeForce RTX 4090でも実行できますか?」という質問に対して量子化版の登場を待つように案内しています。
You can wait for more quantizied versions. The official version is in BF16 and requires over 45GB— Z.ai (@Zai_org) January 19, 2026
