Metaが動画内の物体を切り抜くAIモデル「SAM 3」の複数オブジェクトの追跡能力を向上した「SAM 3.1」をリリース


Metaは2025年11月、画像や動画内のオブジェクトを検出・分割・識別するためのAIモデル「Meta Segment Anything Model 3(SAM 3)」を発表しました。現地時間の2026年3月27日、SAM 3の複数オブジェクトを追跡する能力を向上したバージョン「SAM 3.1」をMetaがリリースしました。
We’re releasing SAM 3.1: a drop-in update to SAM 3 that introduces object multiplexing to significantly improve video processing efficiency without sacrificing accuracy.
We’re sharing this update with the community to help make high-performance applications feasible on smaller,… pic.twitter.com/xfMaBdSkqV— AI at Meta (@AIatMeta) March 27, 2026
SAM 3.1: Faster and More Accessible Real-Time Video Detection and Tracking With Multiplexing and Global Reasoning
SAM 3はプロンプトに基づいて画像や動画内のオブジェクトを検出・セグメント化・追跡できる統合モデルです。たとえば「犬」や「黄色いスクールバス」のように短いテキストを入力したり、範囲指定やクリックで動画内のオブジェクトを指定したりすることで、画像や動画内から指定したオブジェクトを切り抜くことができます。
Metaが動画内の物体を識別して切り抜けるAIモデル「SAM 3」を発表 - GIGAZINE

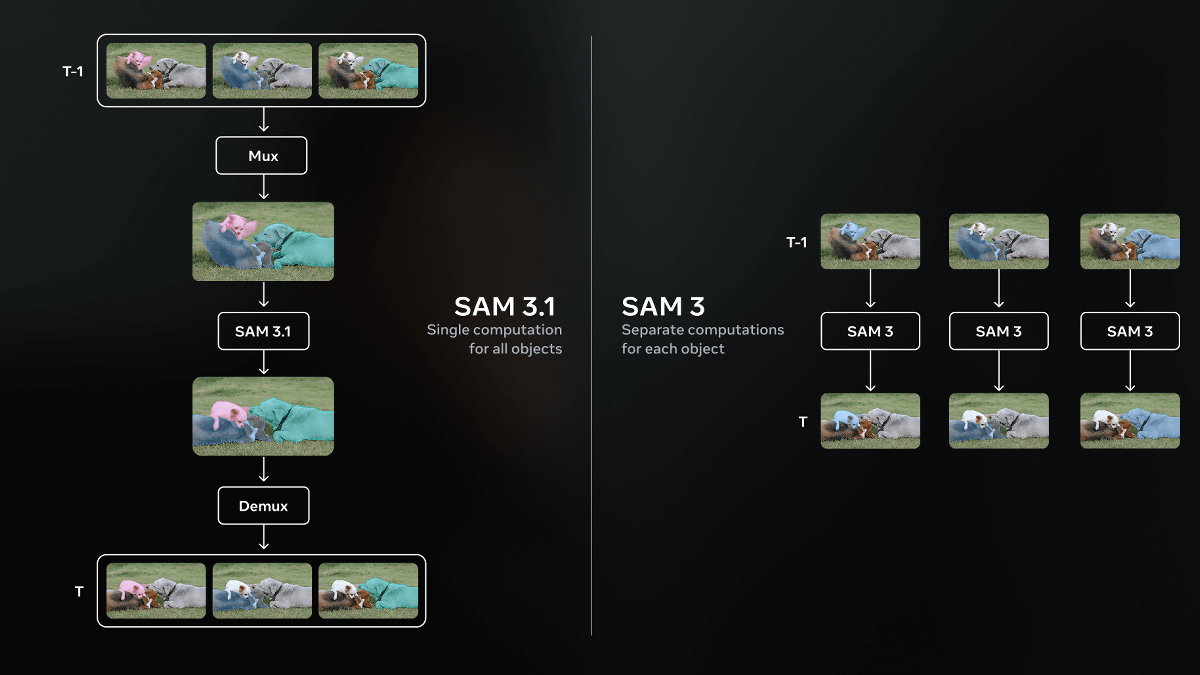
3月27日、MetaはSAM 3の性能を向上させたバージョンであるSAM 3.1をリリースしました。SAM 3.1では「object multiplexing(オブジェクト多重化)」を導入することで、精度を犠牲にすることなく動画の処理効率を大幅に向上させたとしています。
オブジェクト多重化により、SAM 3.1は単一のフォワードパスで最大16個のオブジェクトを追跡できるようになりました。かつては追跡したい各オブジェクトごとに専用のパスが必要でしたが、SAM 3.1は追跡対象のオブジェクトを同時に処理し、冗長な計算やボトルネックを排除したとのこと。
Metaは「このアプローチにより、中程度の数のオブジェクトを含むビデオの処理速度が2倍になり、単一のH100 GPU上でのスループット(単位時間当たりの処理能力)が毎秒16フレームから32フレームに向上します」と説明しています。

以下のグラフは、縦軸が単一のH100 GPUによる動画の処理能力(FPS)、横軸が追跡するオブジェクトの数を表したもの。SAM 3(ピンク色の線)とSAM 3.1(青い線)の性能を比較すると、オブジェクトの数が増えるほど性能の開きが大きくなり、オブジェクトが128個になると実に7〜8倍ほどの性能差になることがわかります。

SAM 3.1のモデルを含むチェックポイントはHugging Faceでダウンロード可能です。
facebook/sam3.1 · Hugging Face
https://huggingface.co/facebook/sam3.1
