GPT��Llama��Grok�ʤɤ��ޤ��ޤ��絬�ϸ����ǥ�Υ������ƥ�������������LLM Architecture Gallery��


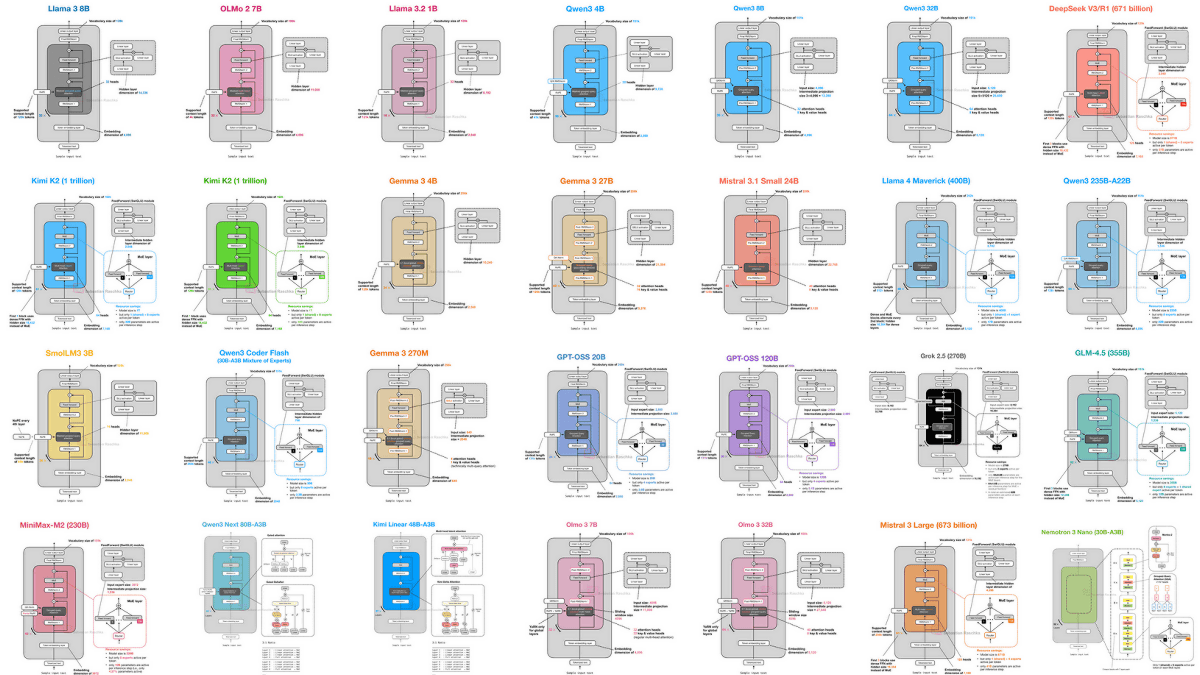
OpenAI��GPT�������xAI��Grok��Meta��Llama�ʤɤ��ޤ��ޤ��絬��������ǥ���¸�ߤ��ޤ����������ι�¤���������LLM Architecture Gallery�פ�����饤��Ǹ�������Ƥ��ޤ���
LLM Architecture Gallery | Sebastian Raschka, PhD
https://sebastianraschka.com/llm-architecture-gallery/
https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
AI����Է����˥��Ǥ��륻�Х�����饷�奫��ϡ�OpenAI��2019ǯ��ȯɽ����GPT-2��2025ǯ��ȯɽ���줿DeepSeek V3��Llama 4����٤�ȡ���ǥ��ι�¤Ū����ʬ���ȤƤ�褯���Ƥ���Ȼ�Ŧ���֤��������٤��ʲ��ɤ��ǡ��䤿���������˲��Ū���Ѳ����ܤˤ��Ƥ����ΤǤ��礦��������Ȥ�ñ��Ʊ���������ƥ�����δ��פ���夲�Ƥ�������ʤΤǤ��礦�����פȵ�������Ƥ��ޤ���
�絬��������ǥ��Υѥե����ޥ˱ƶ��������Ǥˤϥǡ������åȤ�ȥ졼�˥�ˡ���ϥ��ѡ��ѥ����ʤɤ��ޤ��ޤʤ�Τ�����ޤ������������絬��������ǥ��ˤ�ä��礭���ۤʤꡢ¿���ξ��Ͻ�ʬ��ʸ����Ƥ��ʤ�������Ӥ�������ȤΤ��ȡ�
���Τ���饷�奫��ϡ��絬��������ǥ��γ�ȯ�Ԥ��ɤΤ褦�ʼ���ȤߤƤ���Τ����Τ�ˤϡ��������ƥ����㼫�Τι�¤Ū�Ѳ��ڤ��뤳�Ȥ���Ω�Ĥȼ�ĥ���絬��������ǥ��Υ������ƥ�������������LLM Architecture Gallery�פ�������ޤ�����
LLM Architecture Gallery�ˤϤ��ޤ��ޤ��絬��������ǥ����Ǻܤ���Ƥ��ꡢ����å�����ȿޤ뤳�Ȥ��Ǥ��ޤ����������������ǿޤ���������Ƥ���Τϰʲ�����ǥ��Ǥ���
��Llama 3 8B
��OLMo 2 7B
��DeepSeek V3
��DeepSeek R1
��Gemma 3 27B
��Mistral Small 3.1 24B
��Llama 4 Maverick
��Qwen3 235B-A22B
��Qwen3 32B
��Qwen3 4B
��Qwen3 8B
��SmolLM3 3B
��Kimi K2
��GLM-4.5 355B
��GPT-OSS 120B
��GPT-OSS 20B
��Grok 2.5 270B
��Qwen3 Next 80B-A3B
��MiniMax M2 230B
��Kimi Linear 48B-A3B
��OLMo 3 32B
��OLMo 3 7B
��DeepSeek V3.2
��Mistral 3 Large
��Nemotron 3 Nano 30B-A3B
��Xiaomi MiMo-V2-Flash 309B
��GLM-4.7 355B
��Arcee AI Trinity Large 400B
��GLM-5 744B
��Nemotron 3 Super 120B-A12B
��Step 3.5 Flash 196B
��Nanbeige 4.1 3B
��MiniMax M2.5 230B
��Tiny Aya 3.35B
��Ling 2.5 1T
��Qwen3.5 397B
��Sarvam 105B
��Sarvam 30B

���Ȥ��С�Llama 4 Maverick�פ�å�����ȡ��������ƥ���������ޤ�ɽ������ޤ������ޤ���礹��ˤϥ���å���

���礷���ޤϤ���ʴ��������̱���Ρ�View in article�פ�å�����ȡ�����ǥ��ˤĤ��ƤΥ饷�奫��ˤ�������ɤळ�Ȥ��Ǥ��ޤ���

�饷�奫��Ϥ��ޤ��ޤ��絬��������ǥ��ˤĤ��ơ�����¾����ǥ�����Ӥ��ʤ��鶦������㤤����⤷�Ƥ��ޤ���

���Ȥ���Llama 4��DeepSeek V3�����ˤ褯�����������ƥ��������Ѥ��Ƥ��ꡢ��������Mixture-of-Experts(MoE)�פȤ��������ؽ����ץ���������Ѥ��Ƥ���ȤΤ��ȡ���ʰ㤤�ϡ�Llama 4�Ǥ�Transformer��ǥ������եᥫ�˥���θ�Ψ�������ˡ�Ȥ���Grouped-Query Attention(GQA)����Ѥ��Ƥ���Τ��Ф���DeepSeek V3�Ǥ�Multi-Head Latent Attention(MLA)����Ѥ��Ƥ��������ȤΤ��ȡ�
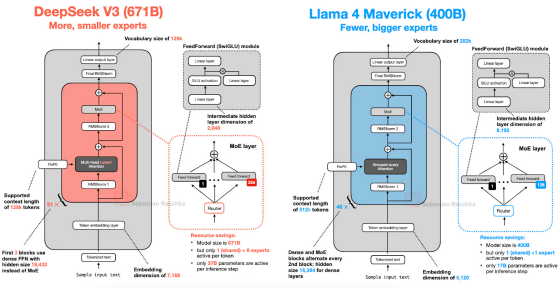
GPT-OSS��Qwen3�������������ݡ��ͥ�Ȥ���Ѥ��Ƥ��ޤ��������ޤ��ޤʽ�����Ԥ�Transformer�֥��å��ο���GPT-OSS��24�ĤǤ���Τ��Ф�Qwen3��48�ĤȤʤäƤ���ۤ������������ʤɤˤ�㤤������ޤ���

Grok 2.5������Ū�ˤ��ʤ�ɸ��Ū�ʹ�¤�Ƥ����ΤΡ�MoE����������̤Υ����ͥåȥ��(�������ѡ���)�ο���8�Ĥȡ�Qwen3��128�Ĥ���٤Ƥ��ʤ꾯�����Ȥ���������ħ�Ǥ����������߷פǤϤ��¿���Υ������ѡ��Ȥ���Ѥ��뤳�Ȥ��侩����Ƥ��뤿�ᡢGrok�ϸŤ��ȥ�����ȿ�Ǥ��Ƥ���ȤΤ��ȡ��ޤ���Grok���ɲä�SwiGLU�⥸�塼�������Ư���붦ͭ�������ѡ��ȤȤ��ƻ��Ѥ��Ƥ������ⶽ̣�����ȥ饷�奫����������ޤ�����

