OpenAIのGPT-4oに「画像でファインチューニングする機能」が追加される、わずか100枚の画像でタスクの性能が向上



OpenAIが2024年5月にリリースしたAIモデル「GPT-4o」に、2024年10月1日から「画像でファインチューニングする機能」が追加されました。すでにテキストでGPT-4oをファインチューニングする機能は提供されていましたが、画像でのファインチューニングが可能になったことで、視覚検索やオブジェクト検出などの機能を向上させることができます。
🖼 We’re adding support for vision fine-tuning. You can now fine-tune GPT-4o with images, in addition to text. Free training till October 31, up to 1M tokens a day. https://t.co/Nqi7DYYiNC pic.twitter.com/g8N68EIOTi— OpenAI Developers (@OpenAIDevs) October 1, 2024
Introducing vision to the fine-tuning API | OpenAI
OpenAIは10月1日に、GPT-4oを画像でファインチューニングする機能をリリースしました。OpenAIは「GPT-4oで初めてファインチューニングを導入して以来、数十万人もの開発者がテキストのみのデータセットでモデルをカスタマイズし、特定のタスクの性能を向上させてきました。しかし多くの場合、テキストでモデルを微調整するだけでは、期待されるパフォーマンスの向上は得られません」と述べています。
GPT-4oのファインチューニングを行うには、まずファインチューニングのダッシュボードにアクセスし、画面上の「+Create」ボタンをクリックします。

ベースモデル一覧から「gpt-4o-2024-08-06」を選択。
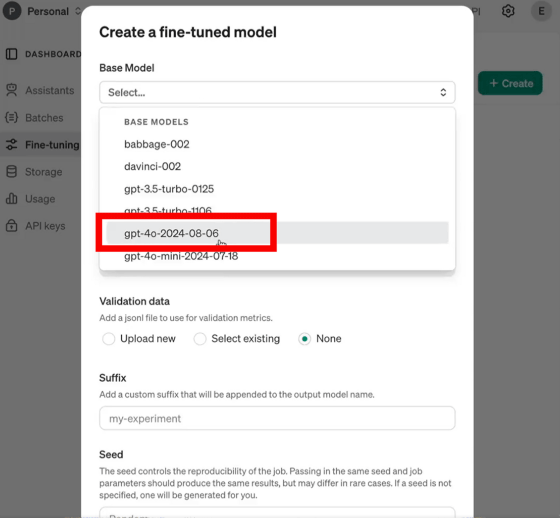
そして画像データセットのファイルを選択し、アップロード用のフォームにドラッグ&ドロップすればOK。画像データセットはあらかじめ適切なフォーマットにしておく必要があるとのことです。OpenAIは、わずか100枚の画像でGPT-4oの画像認識タスクの性能を向上させることができるとしています。

すでにOpenAIはいくつかのパートナーと協力し、実際にGPT-4oの画像ファインチューニング機能を使ってもらっています。東南アジアに拠点を置く配車アプリのGrabは、ドライバーから収集した道路画像を用いてマッピングデータを作成しています。今回Grabはわずか100枚の画像でGPT-4oをファインチューニングし、交通標識の位置や車線の仕切りを正確に特定できるようにファインチューニングしました。
ファインチューニングの結果、GPT-4oの基本モデルと比較して車線を数える精度が20%、速度制限標識の位置推定精度が13%向上したとのことで、以前は手動だったマッピング作業をより適切に自動化できるようになりました。

ドキュメントの処理やUIベースのビジネスプロセスを自動化する企業であるAutomatは、スクリーンショットのデータセットを用いてGPT-4oのファインチューニングを行いました。すると、自然言語による説明が与えられた画面上のUI要素を特定する性能が向上し、自動化エージェントの成功率が16.6%から61.67%に向上したとのことです。また、構造化されていない保険関連文書200枚でGPT-4oをファインチューニングしたところ、情報抽出タスクのスコアが7%向上したことも報告されています。

ウェブサイトやUIの作成・テストを最適化するAIエンジニアリングアシスタントを開発するCoframeは、すでに存在しているウェブサイトの要素に基づいて、新しいブランドセクションを自律的に生成するサービスを提供しています。

Coframeが画像とコードを用いてGPT-4oをファインチューニングすることで、一貫したビジュアルスタイルと正しいレイアウトでウェブサイトを生成するモデルの能力を、基本のGPT-4oと比較して26%向上させられたとのことです。

画像を用いたGPT-4oのファインチューニング機能は最新モデルの「gpt-4o-2024-08-06」でサポートされており、有料のアカウントTierを持つすべての開発者が利用可能。10月31日までは1日あたり100万トレーニングトークンが無料提供されており、11月1日以降のファインチューニングには100万トークンあたり25ドル(約3600円)、入力に100万トークンあたり3.75ドル(約540円)、出力に100万トークンあたり15ドル(約2200円)の費用がかかるとのことです。
