Gemini 3 Proは文書・空間・画面・動画理解で最先端パフォーマンスを実現



2025年11月にリリースされた「Gemini 3 Pro」について、Google DeepMindが「文書・空間・画面・映像の理解で最先端のパフォーマンスを実現する」という資料を公開しています。
Gemini 3 Pro: the frontier of vision AI
https://blog.google/technology/developers/gemini-3-pro-vision/
Google DeepMindのプロダクトマネージャーを務めるローハン・ドーシ氏はGemini 3 Proについて「当社史上最も高性能なマルチモーダルモデルで、文書理解・空間理解・画面理解・動画理解の全領域で最先端の性能を発揮する」と表現しています。
18世紀の商人が残したハンドブックを再構成したもの。
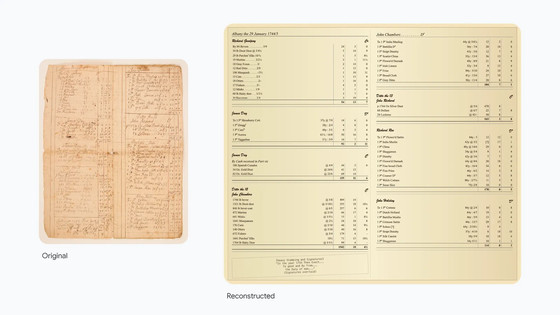
手書きの数式の読み取り。

フローレンス・ナイチンゲール作図のポーラー・エリア・チャートもこの通り。

「空間理解」の分野では、オブジェクトとその意図を識別できるとのこと。
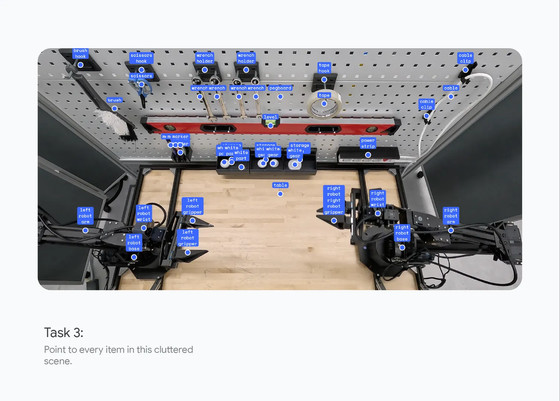
「画面理解」の分野についてはデモ動画が公開されていて、Gemini 3 ProがPC画面上のUIを理解していることがわかります。
Gemini 3 Pro: Screen Understanding Demo - YouTube
「動画理解」では、特にGemini 3 Proは「飛躍を遂げた」とドーシ氏は述べています。10FPSで動画を処理することにより、ゴルフやテニスのスイングのメカニクスの解析などが可能です。また「思考」モードの動画推論により、起きていることを特定するだけでなく「なぜ起きているのか」を理解できます。
なお、Gemini 3 ProはAIモデルの抽象的推論能力を測るベンチマークテストの「ARC-AGI-2」で54%というスコアを記録したことが報告されています。タスクあたりのコストは31ドル(約4800円)で、他のAIモデルよりも高コストですが、圧倒的に高い性能を示すことができます。なお、AIとしてシェアの大きいOpenAIのGPT-5は、スコアは10%だったのに対してコストは1ドル(約156円)弱と低コストです。
We have verified a new SOTA Gemini 3 Pro Refinement technique, authored by Poetiq
54% on ARC-AGI-2, $31/task https://t.co/M5Uo5ZDmXv pic.twitter.com/88y0lIvTCb— ARC Prize (@arcprize) December 7, 2025
