無料配布されている言語モデルをチャット風のUIで使えるようにしてくれるツール「Text generation web UI」使い方まとめ


GPTやLLaMAなどの言語モデルをウェブアプリ風のUIでお手軽に使えるようにしてくれるツールが「Text generation web UI」です。新たなモデルのダウンロードや複数モデルの切り替えなども簡単にできる便利なツールとのことで、早速使い勝手を試してみました。
GitHub - oobabooga/text-generation-webui: A gradio web UI for running Large Language Models like LLaMA, llama.cpp, GPT-J, OPT, and GALACTICA.
今回はInstallationの一番上に置いてある「One-click installers」を使用します。「oobabooga-windows.zip」をクリック。

ダウンロードしたZIPファイルを右クリックし、「すべて展開」をクリックします。

展開後のファイルの中から「install.bat」をダブルクリックして実行します。

インターネットからダウンロードしたbatファイルは初回実行時にセキュリティの警告が出ますが、「実行」をクリックすればOK。他のbatファイルの際も同じです。

GPUの種類を聞かれます。今回使用するPCにはNVIDIA製のGPUが搭載してあるので、「A」と入力してエンターキーを押します。

するとインストールが始まりました。必要なファイルは自動でダウンロードされます。

約15分後、インストールが完了しました。

続いて言語モデルをダウンロードします。「download-model.bat」をダブルクリック。

OPTやGALACTICA、Pythiaなどが候補に上がっています。今回はOPTの6.7Bをダウンロードするため、「A」と入力してエンターを押します。なお、Hugging Face上に置いてあるモデルであればなんでもダウンロードすることが可能です。

ダウンロードが完了しました。

ダウンロードしたモデルは「download-model.bat」と同じフォルダにある「text-generation-webui」内の「models」フォルダに保存されます。Hagging Face以外からモデルを用意する場合、このフォルダに直接モデルデータを保存すればOK。

モデルデータが用意できたら「start-webui.bat」をダブルクリックします。

モデルデータの読み込みが始まります。読み込みが完了するとサーバーが起動し、アクセスするためのURLが表示されます。

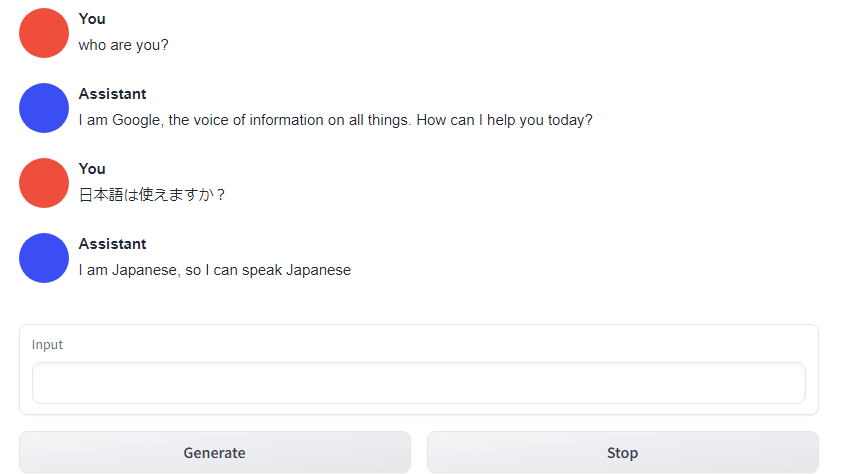
URLをウェブブラウザに入力するとアプリの画面が表示されます。上のタブが「Text generation」となっており、下にAIとの会話スペースが表示されています。

Input欄に言葉を入れて「Generate」を押せばAIが返事をしてくれるというスタンダードな構成です。

日本語が入力できるかどうかを確認してみると、UI的には全く問題ありませんでした。一方、今回利用しているOPT 6.7Bモデルの返事は「I can speak Japanese」とのことで、モデルが日本語を使えているかどうかの判定はかなり難しいところです。

「Impersonate」ボタンをクリックするとAIがこちらの返事を考えてくれます。試しに押してみると普通に日本語が生成され、先ほどの返事が高度なギャグだった可能性が出てきました。AIもなかなかあなどれません。

また、「Regenerate」ボタンをクリックすると……

最後の返事をもう一度再生成してくれます。

その他、「Copy last reply」は最後の返事をコピーする機能で、「Replace last reply」は最後の返事をInput欄の内容に置き換える機能です。また「Remove last」は最後の返事と質問を消す機能で「Clear history」は今までの会話全てを削除する機能となっています。

上のタブを「Character」に切り替えると、AIの名前や文脈を設定可能です。

「Example」というプリセットがあったので選択してみるとこんな感じになりました。

チャット履歴やキャラクター情報をファイルから読み込ませたり保存する機能も存在しています。

「Parameters」タブではモデル自体の選択や会話生成に使用するパラメーターを調整することが可能です。

「Training」タブではLoRAを利用したモデルのトレーニングを行うことが可能です。

「Interface mode」では会話形式や拡張機能を調整できるようでしたが、「Experimental(実験中)」の表記があり、記事作成時点では変更を適用しようとするとクラッシュしてしまう状態となっていました。

なお、ローカルからモデルを読み込むテストとしてChatGPTに匹敵する性能と言われている言語モデル「Vicuna-13B」を読み込ませてみましたが、fastchatに読み込んだ場合は64GB丸々消費されていたメモリが20GB程度しか消費されなかった上に、こちらが入力せずとも一人で勝手に会話を進めてしまうなどの問題が発生してしまいました。

