首相会見の「言葉」はこの10年でどう変わったか?AmiVoice APIで8時間分の音声をテキスト化して見える隠れた社会のトレンドとは?



会議・スピーチ・インタビューなど、さまざまな場面で録音された音声データをテキスト化することのできる「音声認識サービス」は、現代の情報処理において重要な役割を果たしつつあります。中でも、日本発の音声認識エンジン「AmiVoice」は国内シェアNo.1を誇り、25年を超える開発実績による高い認識精度と多様な機能で注目を集めています。さらに、AmiVoiceはAPIが用意されており、とりわけ非同期処理を行うと大量の音声を処理できます。そこで、AmiVoice APIの特徴を活かして、現在および過去における政府の公的演説をテキスト化し、さらにテキストマイニングツールを組み合わせることにより、言葉の使用頻度の変化を分析し、社会のトレンドや政策の変遷を浮き彫りにしてみました。
https://acp.amivoice.com/amivoice_api/
AmiVoice API AmiVoice API アカウントの作成
https://acp.amivoice.com/amivoice_api/regist/
・目次
◆はじめに
◆音声認識1000時間無料キャンペーン
◆AmiVoice APIの概要
◆API呼び出し準備
◆環境構築
◆API呼び出しスクリプトの作成
◆音声ファイルの処理
◆直近のデータを解析
◆5年前のデータを解析
◆10年前のデータを解析
◆直近と10年前のデータを比較
◆まとめ
◆はじめに
政府の方針は国民の声や思いを反映するものであり、世相や社会の空気といったものは必ず政府の発信する「言葉」の端々に表現されているはずです。そこで、政府が公開している膨大な音声記録をテキストデータ化して解析することで、隠れていた「面白いもの」を具体的に見つけてみることにしました。
◆音声認識1000時間無料キャンペーン
まずは、音声記録からテキストデータを作るわけですが、そこで役立つのが音声認識エンジン「AmiVoice」です。2025年12月31日までは無料で1000時間分使えるとのことなので便乗します。
ニュース 音声資産活用キャンペーン―AmiVoice API音声認識1,000時間無料!―
https://acp.amivoice.com/news/news/2025/10/01/7678/

上記のページにある「お申し込みフォーム」ボタンをクリックします。

フォームに必要事項を記入し、「送信」ボタンをクリックすると申し込みが完了し、AmiVoice APIを1000時間分無料で利用できるアカウントを入手できます。既にAmiVoice APIアカウントを持っている場合でも1000時間分の無料利用枠が追加されます。

◆AmiVoice APIの概要
キャンペーンの無料利用枠は非同期インターフェースが対象なので、以下のリファレンスを参考にします。
非同期 HTTP インタフェース | AmiVoice Cloud Platform
https://docs.amivoice.com/amivoice-api/manual/reference-async-http/
すると、呼び出すエンドポイントは2つあることがわかります。
1つ目はジョブを作成し、セッションIDを取得するためのエンドポイントです。
POST https://acp-api-async.amivoice.com/v2/recognitions
2つ目はセッションIDを指定してジョブの状態を確認し、結果を取得するためのエンドポイントです。
GET https://acp-api-async.amivoice.com/v2/recognitions/{session_id}
ジョブの状態は2つ目のエンドポイントからのレスポンスで確認でき、状態遷移図を書くと以下のようになります。状態が「completed」になるとテキスト化が完了し、結果を取得できるとのこと。

◆API呼び出し準備
AmiVoice APIの認証にはパスワードとAPPKEYが必要なので、アカウントの管理画面から事前に取得しておきます。管理画面に移動するにはAmiVoice APIのトップページ上部にある「ログイン」をクリックします。

ログイン画面が表示されたらアカウントIDとパスワードを入力し、CAPTCHA認証を行って「ログイン」ボタンをクリックします。

ログインに成功するとAmiVoice APIの管理画面「マイページ」が表示されます。

下にスクロールしていくと「接続情報」があるので、そこから「サービスパスワード」をコピーして取得しておきます。また、初期状態で「APPKEY」が一つ存在しているので、これもコピーして取得します。

◆環境構築
エンドポイントを定期的に呼び出す必要があるので、bashのスクリプトで実装することにしました。そこで実行環境はWSL上のUbuntuとし、必要なツールをインストールしていくことにします。
まずはMicrosoft StoreよりUbuntuをインストールします。記事作成時点で最新のLTS版であるUbuntu 22.04.1 LTSを選択し、「入手」ボタンをクリックしてインストールします。

インストールが完了すると「入手」ボタンが「開く」ボタンに変わるので、「開く」ボタンをクリックしてUbuntuを起動します。

この時点でWSLがインストールされていない場合はUACプロンプトが表示され、「はい」ボタンをクリックすると続けて以下のウィンドウが表示されるので、任意のキーを押してWSLをインストールします。

WSLのインストールが完了すると一旦Windowsを再起動します。その後Ubuntuを起動すると、初回起動時はユーザー名とパスワードの設定が求められるので、任意のユーザー名とパスワードを入力して設定します。入力後、プロンプトが表示されるようになればWSL上のUbuntuが使える状態になっています。

次に、Ubuntuを最新の状態にしておきます。以下のコマンドを実行してパッケージリストを更新し、アップグレードを行います。
sudo apt update
sudo apt upgrade -y
次に、以下のコマンドを実行してcurlとjqをインストールします。curlはAPI呼び出し、jqはAPIのレスポンスの整形および検索に使用します。おそらくデフォルトの状態でcurlはインストールされていると思いますが、念のため実行しておきます。
sudo apt install -y curl
sudo apt install -y jq
◆API呼び出しスクリプトの作成
先程の状態遷移図を参考に、AmiVoice APIを呼び出すbashスクリプトを作成していきます。まずは任意のディレクトリにて、スクリプトを作成します。
#! /usr/bin/bash
# AmiVoice API using sample
# ref. https://docs.amivoice.com/amivoice-api/manual/tutorial-long-speech-transcription
service_id='【アカウント名】'
service_pw='【管理画面から取得したパスワード】'
app_key='【管理画面から取得したAPPKEY】'
end_point='https://acp-api-async.amivoice.com/v2/recognitions'
# パラメータで渡されたファイル名を取得
if [ -z "$1" ]; then
echo "Usage $0 [file_name]"
exit 0
elif [ ! -f $1 ]; then
echo "File not exists."
exit 1
fi
file_name=$1
# 音声認識のリクエスト
response=`curl -X POST ${end_point} \
-F d=-a-general \
-F u=${app_key} \
-F "a=@${file_name}"`
temp=`echo ${response} | jq '.sessionid'`
session_id=${temp//'"'/''}
echo "Response:${response}"
echo "Session ID:${session_id}"
loop_fg=0
loop_interval=10
status=''
# 処理が完了するまでループ
while [ ${loop_fg} -eq 0 ]; do
# 一時停止
sleep ${loop_interval}
# ジョブの状態を取得
response=`curl -H "Authorization: Bearer ${app_key}" \
${end_point}/${session_id}`
temp=`echo ${response} | jq '.status'`
status=${temp//'"'/''}
echo "End point:${end_point}/${session_id}"
echo "Response:${response}"
echo "Status:${status}"
# 状態判定
if [ "${status}" = "completed" ]; then
loop_fg=1
elif [ "${status}" = "error" ]; then
echo ${response} | jq '.error_message'
exit 2
fi
done
# 結果を整形して出力
echo ${response} | jq > "${file_name%.*}.json"
想定している使用方法は、スクリプトに実行権限を付与し、以下のように音声ファイルを引数として渡して実行する形です。
chmod +x amivoice_api.sh
./amivoice_api.sh sample_audio.wav
◆音声ファイルの処理
音声認識の素材には、YouTubeにある日本政府公式の首相官邸チャンネルの動画から、比較的長尺の演説動画を選び、述べ8時間分の音声を保存したものを使用しました。ピックアップ対象は、以下の期間としました。
・直近の動画:2.5時間強
・5年前の動画:2.5時間強
・10年前の動画:2.5時間強
注意が必要な点として、APIに渡せる音声フォーマットが決まっています。下記のドキュメントを確認し、対応している音声フォーマットでファイルを作成します。
音声フォーマット | AmiVoice Cloud Platform
https://docs.amivoice.com/amivoice-api/manual/audio-format/
作成した音声ファイルをスクリプトで処理すると、以下のようなJSONファイルが生成されました。
{
"status": "completed",
"session_id": "019a2e4878ae0a301d7794c0",
"service_id": "【アカウント名】",
"audio_size": 133935182,
"audio_md5": "8b0120feba05841e92fcb0d1bab96fc3",
"segments": [{
"results": [{
"tokens": [{
"written": "今日",
"confidence": 1.0,
"starttime": 1146,
"endtime": 1594,
"spoken": "きょう"
}, {
"written": "から",
"confidence": 1.0,
"starttime": 1594,
"endtime": 1802,
"spoken": "から"
}, {
"written": "始め",
"confidence": 1.0,
"starttime": 1802,
"endtime": 2186,
"spoken": "はじめ"
}, {
"written": "ます",
"confidence": 1.0,
"starttime": 2186,
"endtime": 2634,
"spoken": "ます"
}, {
:
:
【略】
:
:
}, {
"written": "ありがとうございます",
"confidence": 0.98,
"starttime": 681286,
"endtime": 682326,
"spoken": "ありがとうございます"
}, {
"written": "。",
"confidence": 0.97,
"starttime": 682326,
"endtime": 682534,
"spoken": "_"
}],
"confidence": 0.977,
"starttime": 661750,
"endtime": 682534,
"tags": [],
"rulename": "",
"text": "組み替えていく、あるいは…【略】…ありがとうございます。"
}],
"text": "組み替えていく、あるいは…【略】…ありがとうございます。"
}],
"utteranceid": "20251029/13/019a2e49d4ef0a3051c539d0_20251029_134621",
"text": "今日から始めます。やっぱりねこれから先…【略】…ありがとうございます。",
"code": "",
"message": ""
}
得られたJSONファイルのルート直下にあるtextの値が動画全体の音声をテキスト化した文字列になっています。これを期間ごとにマージし、テキストマイニング用のデータとします。テキストマイニングツールには以下のサイトを使用します。
AIテキストマイニング by ユーザーローカル
https://textmining.userlocal.jp/
◆直近のデータを解析
直近のデータとして用いたのは、2025年10月に日本で初めて総理大臣に選出された高市早苗首相の所信表明演説などです。
・ワードクラウド(出現頻度順)

・ワードクラウド(スコア順)

・単語出現頻度
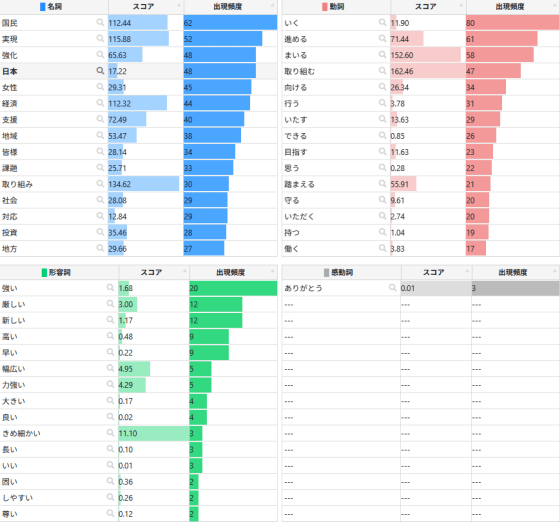
「女性」という単語が目立つのが特徴的です。それ以外では「経済」「賃上げ」といった単語も目立ちます。動詞については「進める」「取り組む」「守り抜く」のように、意欲的に行動する言葉が目立ちます。
◆5年前のデータを解析
5年前のデータとして用いたのは、広島・長崎の原爆の日に安倍晋三元首相が行ったスピーチなどです。
・ワードクラウド(出現頻度順)

・ワードクラウド(スコア順)

・単語出現頻度

5年前といえば新型インフルエンザが猛威を振るっていた時期であるだけに、「ワクチン」「接種」「医療従事者」「医療機関」といった単語が目立ちます。動詞で「思う」が特に目立つのも特徴的です。
◆10年前のデータを解析
10年前のデータとして用いたのは、安倍晋三元首相の談話・記者会見などです。
・ワードクラウド(出現頻度順)

・ワードクラウド(スコア順)

・単語出現頻度

「日本」や「世界」「中南米」といった単語が目立ち、また「私達」「皆さん」といった語りかけるフレーズも目立ちます。「経済」や「反映」もそこそこ見られ、「TPP」に関しては当時の世論の関心を反映しています。
◆直近と10年前のデータを詳細に比較
5年前のデータはコロナ禍の影響が強いためいったん省き、直近と10年前のデータについて比較し、さらなる特徴が見られるかを確かめてみます。
・単語分類

直近の動画にのみ現れる単語として「AI」があるのがなるほどと思わされます。また「物価高」も最近の世相が反映されています。形容詞に着目すると、10年前に比べて直近は「息苦しい」「生きづらい」「痛ましい」といったネガティブな単語が目立ちます。
・特徴語マップ

直近の動画では「きめ細かい」という単語が特徴的です。対して、10年前の動画では「揺るぎない」や「粘り強い」といった力強い単語が特徴的です。
・ネガポジマップ

10年前の動画に多い単語はネガティブからポジティブまで均等に分散しているのに較べて、直近の動画に多い単語はネガティブに偏っている傾向がみられます。
・単語の出現比率

一部繰り返しとなりますが、直近の動画では「女性」「賃上げ」「取り組む」が目立ち、「特徴語マップ」で見た「きめ細かな」も印象的です。10年前の動画では「私達」に加えて「安い」や「美味しい」といった形容詞が特徴的です。
◆まとめ
今回の調査で、AmiVoice APIを活用することにより、様々な解析を試行するための大量のテキストデータを簡単に得られることがわかりました。どのような解析ツールを用いてどういった切り口でデータを処理するかを検討することで、音声認識APIの有用性はとても幅広く存在していることがわかります。そんなAmiVoice APIを無料で1000時間分試せるキャンペーンが2025年12月31日まで実施中なので、音声認識APIを利用したテキスト解析を試してみたい場合、大量の音声データの処理を試せる絶好の機会です。
ニュース 音声資産活用キャンペーン―AmiVoice API音声認識1,000時間無料!―
https://acp.amivoice.com/news/news/2025/10/01/7678/
