AIが科学者にとってどれだけ役立つかを測定できるベンチマークテスト「LifeSciBench」をOpenAIが公開


OpenAIがAIベンチマークテスト「LifeSciBench」を2026年6月17日に発表しました。LifeSciBenchは「AIが生命科学研究者にとってどれだけ有用か」を測定できるベンチマークテストで、従来の科学系テストと比べて実際の運用に沿った評価が可能とされています。
Introducing LifeSciBench | OpenAI
https://openai.com/index/introducing-life-sci-bench/
そこで、OpenAIは科学者が日常的に処理しているタスクを「科学的根拠の取り扱い」「分析」「設計と最適化」「科学的考察」「検証と運用」「科学的知見の臨床意思決定への結びつけ」「科学的コミュニケーション」の7種に分類し、バイオテクノロジーや創薬に携わる173人の科学者と協力して課題を作成しました。各課題は「科学者が知識豊富な共同研究者に依頼する」という形式で構成されており、AIは関連する資料の内容を確認しつつ自由記述形式で回答を生成する必要があります。
LifeSciBenchではAIに合計750件のタスクを与えます。AIには図表や化学構造ファイルなどを含む1062件の添付資料が与えられ、タスクの53%は少なくとも1つの資料を参照するように設計されています。

AIが生成した回答は「科学者が期待する適切な詳細度に達しているか」「根拠は正しいか」「書式は正しいか」といった多様な基準で評価され、各基準を満たすとスコアが加算される仕組みです。これにより、LifeSciBenchは「AIが実際に科学者にとってどれだけ役立つか」を測定することができます。

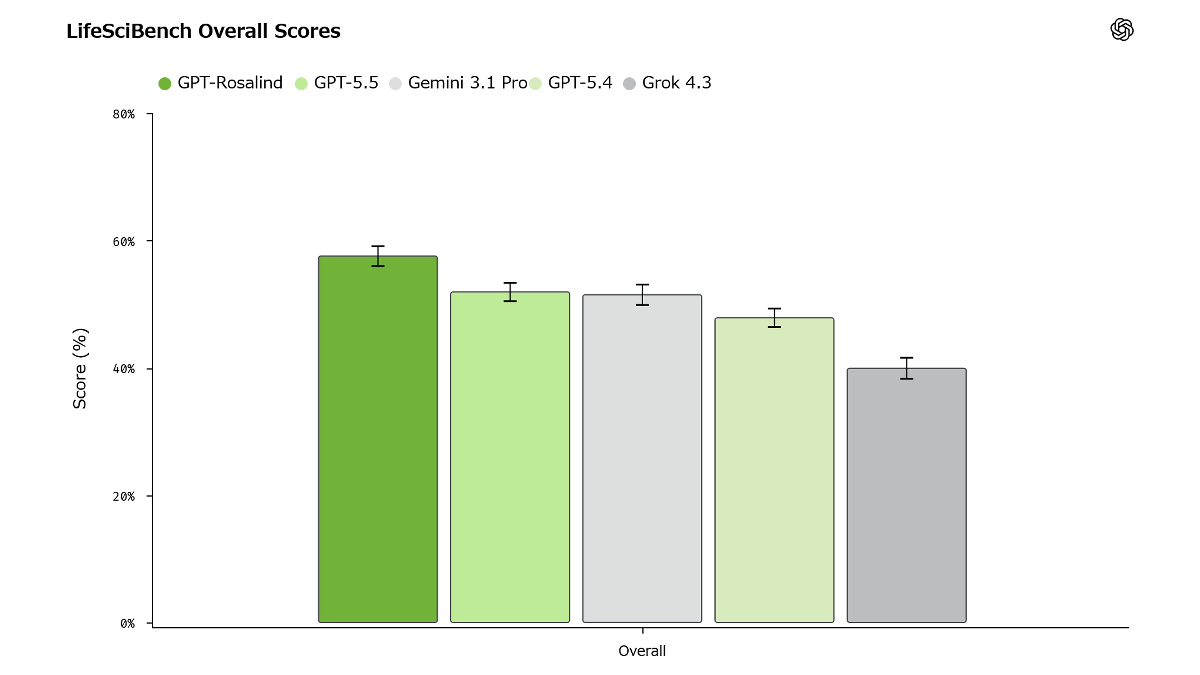
以下のグラフは複数のAIモデルのLifeSciBenchスコアを示しており、高い順に「GPT-Rosalind」「GPT-5.5」「Gemini 3.1 Pro」「GPT-5.4」「Grok 4.3」と並んでいます。ちなみに、GPT-RosalindはOpenAIの科学特化AIモデルで、記事作成時点ではGPT-5.5をベースとしています。

GPT-RosalindとGPT-5.5の性能比較グラフが以下。7種のタスクすべてでGPT-Rosalindの方が高いスコアを記録しました。

なお、OpenAIはLifeSciBenchの発表と同日に「GPT-5.4で創薬研究を補助することができた」とするレポートを公開し、自社製AIが科学技術の発展に寄与していることをアピールしています。
A near-autonomous AI chemist improves a challenging reaction in medicinal chemistry | OpenAI
https://openai.com/index/ai-chemist-improves-reaction/

