
秒間100枚以上の画像を生成できる爆速画像生成パイプライン「StreamDiffusion」が登場


ソースからのデータ入力、機械学習モデルへのデータ出力、学習パターンの調整といった一連の処理構造「パイプライン」をリアルタイム画像生成のために最適化した「StreamDiffusion」が登場しました。
[2312.12491] StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation
GitHub - cumulo-autumn/StreamDiffusion: StreamDiffusion: A Pipeline-Level Solution for Real-Time Interactive Generation
https://github.com/cumulo-autumn/StreamDiffusion/tree/main
大変お待たせしました!本日arXivにて公開された私達の論文「StreamDiffusion」について
GitHubリポジトリの方も公開しました!100fps以上出すことも可能です!
詳しくは論文、リポジトリのREADMEをご確認ください!#StreamDiffusion
論文:https://t.co/4zQKFyPKgj
GitHub:https://t.co/U1ufvRR9cq https://t.co/5hO1UXT4Ya— あき先生 / Aki (@cumulo_autumn) December 21, 2023
制作者らによると、既存の拡散モデルはテキストや画像のプロンプトから画像を生成することには長けているものの、リアルタイムのやりとりでは性能が十分でないことがあったそうです。このような制限は、メタバースやライブビデオストリーミングのような「連続的な入力」を伴うシナリオにおいて特に顕著で、この問題に対処するために新しいアプローチを考案したとのこと。
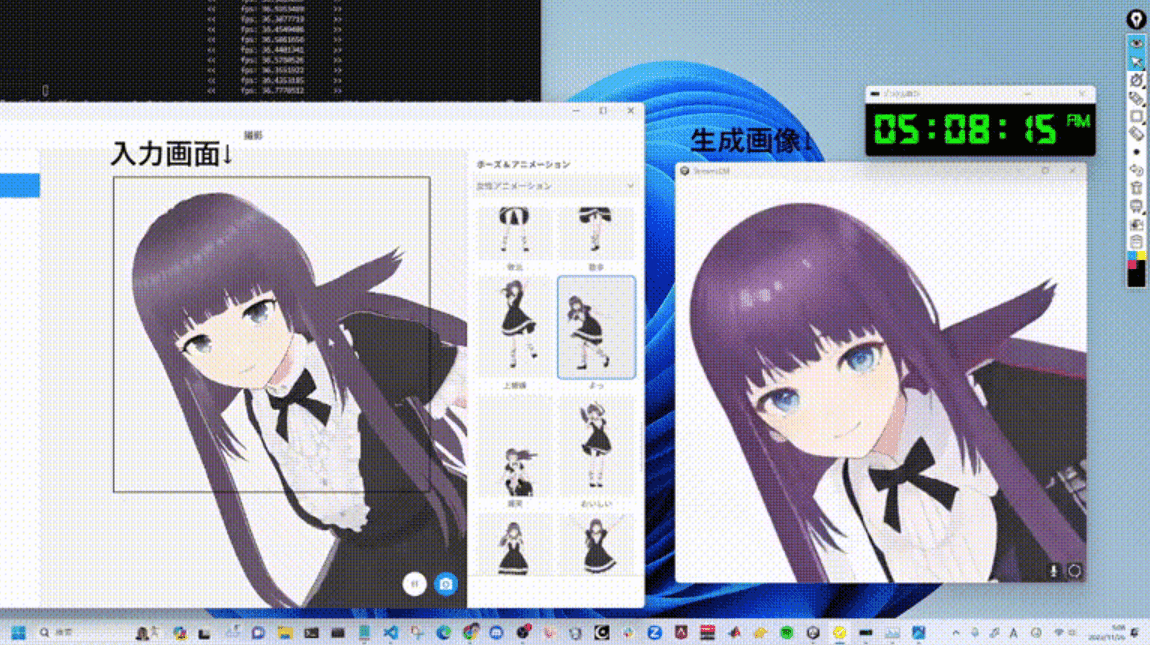
RTX 4090、Core i9-13900K、Ubuntu 22.04.3 LTSの環境でStreamDiffusionを用いて画像を生成したところ、SD-turboモデルのText-to-Image処理で106.16fpsという3桁超の数値をたたき出したそうです。

テキストからイメージをリアルタイムで生成する様子を映したGIFも公開されています。以下の画像をクリックすることで公開ページにジャンプします。

また、画像生成の様子は以下の動画でも確認できます。
リアルタイムで画像を生成する「StreamDiffusion」のデモ映像 - YouTube
StreamDiffusionの特徴は、従来の待ち時間と対話のアプローチを排除し、バッチ処理によるデータ処理の効率化を図る「Stream Batch」、計算の冗長性を最小限に抑える「RCFG」、GPUの使用効率を最大化する「Stochastic Similarity Filter」などの機能が備わっていることです。
Stochastic Similarity Filterは「前フレームからあまり変化しない場合の変換処理を減らすことで、GPUの負荷を軽減する」というもの。Stochastic Similarity Filterの効果を示す以下のGIFアニメーションでは、画像を爆速で出力しつつもGPU使用率が低い状態を保てていることが分かります。

StreamDiffusionのGitHubリポジトリは以下からアクセスできます。
StreamDiffusion/README-ja.md at main · cumulo-autumn/StreamDiffusion · GitHub
https://github.com/cumulo-autumn/StreamDiffusion/tree/main






