
PCテクノロジートレンド 2022 - プロセス編


●プロセス編 - 2022年のTSMC
2022年の幕開けに、パーソナルコンピュータのハードウェア技術の動向を占う「PCテクノロジートレンド」をお届けする。まずは業界のあらゆる活動に大きな影響を及ぼす半導体プロセスの動向について紹介したい。
***
皆様、あけましておめでとうございます。本年もよろしくお願いします。
2020〜2021年はコロナに明け暮れた感もあるが、引き続きオミクロン株が猛威を振るっており、まだこの先の動向がどうなるかは判らない。もっとも企業としても、その辺りを勘案しながらビジネスを進めており、その意味ではコロナを気にしつつも製品は投入され続けているわけで、今年も色々動きがありそうである。という事で何時もの通り、今年の予測などを。まずはProcess関連の動きから(Photo01)。

Photo01: 今年は預かり猫シリーズ(里子に出した連中)で行こうかと。トップバッターは2003年にやってきた3猫。へその緒が付いた状態で来襲、離乳のタイミングで元々3匹を保護をした友人宅に戻っていった。
○TSMC(Photo01)
ご存じの通り現時点では業界最大かつ業界最先端の製造能力を持つTSMC。PC業界で言ってもIntel、AMD、NVIDIA(PC向けはまだSamsung:HPC向けがTSMC)がTSMCに委託または委託予定、というあたりで何をかいわんやである。
2021年は熊本に新工場を作るという話になっているが、こちらは産業向けがメインとなる28/22nmノードである。ただそれ以前にアリゾナに新Fab(Fab 24)を建設予定であり、しかも当初はMegaFab(ウェハ生産量が300mm換算で月産25000枚程度)という話だったのが、いつの間にかそれが6棟に増え、GigaFab(同月産10万枚以上)に昇格しているという騒ぎである。またここに後工程工場を追加するという報道も出てきており、これが実現するとちょっとした規模の生産拠点となる。
といっても、TSMCは既に台湾にGigaFabを5つ(Fab 3/6/12/15/18)持っており、今後Fab 18の増強(Phase 3〜6:2022年中に稼働)とFab 20(2024〜2025年に稼働予定)が予定されているから、メインは引き続き台湾ということになる。なおFab 24の稼働予定は2024年という話なので、少なくとも現時点では考慮しても仕方ないところである。
なお先端プロセスに関しては、7nm世代がFab 15、5nmがFab 18のPhase 1〜3、3nmがFab 18 Phase 4〜6(7もある、という話も出ている)、2nmがFab 20の予定である。Fab 21は5nmという話だが、ひょっとすると3nmになるかもしれない。
さてそのTSMCであるが、更にプロセスが複雑化している。一覧で示すと
N7 : TSMCの最初の7nmプロセス。ArF液浸+マルチパターニング。TSMCによれば昨年7月の時点で既に10億個のN7ベースのチップが出荷されたとしている。
N7P : N7の性能向上型。N7とプロセス互換性があるため、N7の設計そのままで移行可能。ArF液浸+マルチパターニング。AppleがA13でN7Pを採用したが、性能向上率はN7比で7%(もしくは同一性能で10%の消費電力減)とそれほど大きくない。
N7+ : N7の製造プロセスの一部(トランジスタ層と一部の配線層)をEUV露光に切り替えたもの。N7と設計の互換性がないので、N7からそのままの移行はできない。そのあたりもあって、あまり多くのチップでは採用されていない。
N6 : N7の一部をEUV化したという意味ではN7+に近いが、N7+との最大の違いはN7と設計の互換性があること。N7あるいはN7Pを利用していたデザインはそのままN6に移行可能とされる。またN7+よりEUV露光を使う配線層が1層多い。2020年から量産を開始しており、2021年末では7nm世代の凡そ半分がこのN6に移行している。
N5 : 7nm世代とは全く互換性の無い新ノード。露光はEUV。こちらも2020年から量産を開始しており、現時点では最新のプロセスノードとなっている。
N4 : 2021年中にRisk Productionがスタートしており、2022年中に量産をスタートする予定だが、意図的にかどうかは知らないが性能などについては語られていない。ただ後述するN4Pの数値から算出すると、N4はN5比で4.7%の性能向上が期待できるとなり、大きくは上がらないといったところか。またN5比でマスクを幾つか減らせる、と説明されているのでおそらくはより配線層へのEUV適用が進んだものと思われる。また設計ルールやSpice(動作のアナログシミュレーション)、IPの互換性を保つと説明されている。ここから見るに、設計そのものは若干の手直しが必要で、N5向けに設計したチップをそのままN4に持ってゆく訳には行かないようだ。またトランジスタ密度そのものはN5と同等と思われる。
N4P : 2021年10月に発表された、N4の改良版。N5と比較して性能を11%改善できるほか、消費電力効率とトランジスタ密度をそれぞれ22%/6%向上させられると説明されている。ちなみにN4比では性能が6%改善となっている。設計そのものはN5/N4と互換性は無いが、容易に移行可能と説明されており、最初のN4PのTape outは2022年後半と説明されている。ということは量産シリコンが出てくるのは早くても2023年前半期と予想される。
N4X : 2021年12月に発表されたN4Pの高性能特化版。N4PはHPCからMobileまで、つまり高性能寄りにも低消費電力寄りにも出来る汎用向けプロセスであったが、N4XはHPCに特化する、つまり性能を上げる事を目的としたカスタム版である。具体的にはCPUとかGPU、それとCloud AI向けプロセッサなどで利用される形で、Mobile向けSoCでの採用は無いだろう(Apple M2以降での採用は微妙なところだが)。そのN4X、1.2V動作の場合にN5比で15%、N4P比でも4%の性能向上が期待でき、1.2Vを超える電圧だと更に性能向上が得られると説明している。またN4XはN5と同じデザインルールでの設計が可能である。つまりN5を使って製造されたCPUとかGPUのプロセスアップグレードパス、として提供される模様だ。もっともその分消費電力はかなりひどいことになりそうだし、トランジスタ密度向上は期待でき無そうである。このN4X、2023年前半にRisk Production開始とされているので、量産開始は早くても2023年末、現実問題としては2024年になりそうである。
N3 : こちらもN7→N5と同様に、5nm世代とは全く互換性の無いノードである。そしてTSMCはSamsungと異なり、この世代でもトランジスタ構造はFinFETのままである。さて、このN3であるが当初発表ではN5比でトランジスタ密度が1.7倍、性能向上が10〜15%の予定とされていた。ところが2021年10月に行われたTSMC 2021 Online Open Innovation Platform Ecosystem Forumにおける説明では、トランジスタ密度が1.6倍、性能向上が11%となり、その代わり消費電力は27%削減と説明されている(Photo02)。またこのN3にはHPC向けの構成であるN3 HPCと、更にこれに対してDTCO(Design Technology Co-Optimization:設計・製造協調最適化)を施したN3 HPC+DTCOの場合の性能も示されており、例えば0.9V動作ならN3と比較しても最大12%高速化できるとしている(Photo03)。

Photo03: 横軸が性能、縦軸が消費電力である。ちなみに、N5とN3の0.9Vの消費電力はほぼ同じだが、N3+DTCOでは結構引きあがっている事に注意。
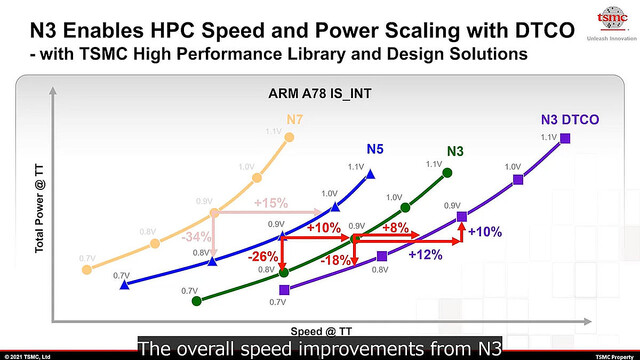
Photo03: 横軸が性能、縦軸が消費電力である。ちなみに、N5とN3の0.9Vの消費電力はほぼ同じだが、N3+DTCOでは結構引きあがっている事に注意。
このN3、こちらでも触れられているが、2021年中にRisk Productionがスタートしており、2022年第2四半期あたりに量産がスタートする、とされている。ただなにしろ当初はそれほどスループットが高くない(なにしろ生産拠点であるFab 18 Phase 4〜6は現時点ではまだ完成しておらず、完成して製造設備がフル稼働状態になるまでには軽く1年は掛かるだろう)と予測され、しかも当初はほぼ全量Appleが持ってゆく。なので、Apple「以外」の量産に入るのは2023年以降になると予測される。なので2023〜2024年はN5/N4P/N4X/N3が入り乱れる格好で量産が行われることになりそうだ。このN3もまた奪い合いになりそうではある。
N2 : TSMC初のGAAを利用するノードである。こちらは2024年以降の量産開始(当初は2025年という話だったが、これを前倒ししているという話も出ている)なので、Risk Productionは早くても2023年後半とかになるだろう。こちらに関してはまだ「やる」という以上の情報が出てきていないのが正直なところである。
といった具合になっている。また、今のところは一切情報は無いが、過去の経緯で考えるとN3とN2の間にもう一つ二つ、プロセスが挟まっても不思議ではない。N3PなりN3Xなりが後追いで追加され、2023年後半〜2024年に量産開始、という事になりそうな気もする。
さてこのTSMCのプロセス、スマートフォン向けSoCやAIプロセッサ向けに奪い合いが始まっている訳だが、当然PC向けにも奪い合いが始まっている。詳しくは後述するが、比較的確実と見られているだけで
N6: Intel Alchemist、AMD Navi 24、AMD Zen 4 IOD、AMD CDNA 2.0
N5: AMD Navi 31?、NVIDIA GA200?、AMD Zen 4 CCD、Intel Alder Lake
N3: AMD Zen 5 CCD、Intel Raptor Lake GPU、NVIDIA GA300?
辺りがぱっと出てきて、恐らく今後は更に増えるだろう。
またTSMCはPackagingに関してもやはり進んでいる。Photo04が現在TSMCが提供しているPackaging技術の一覧である。
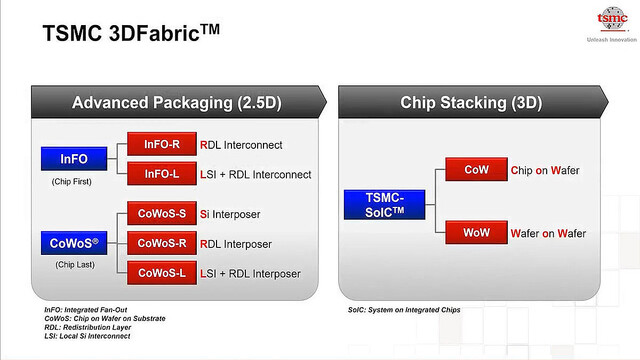
Photo04: InFOは今のところPC向けの適用は無いが、今後Chromebook向けとかには採用される可能性がある。
ここで、
CoWoS: いわゆる2.5D Stackingで、HBM/HBM2/HBM2E/HBM3などの接続は今のところこれに頼る必要があるし、GPUだけでなくAIチップや一部CPUにも利用されている(富士通のA64fxなど)。基本となるのがCoWoS-Sで、これはすべてのチップを搭載するのに必要な、大型のSilicon Substrateを製造し、この上にチップを載せる構造である。ただチップの大型化に伴い、全てのチップを載せきれるSilicon Interposerを製造するのが難しくなってきた。Radeon Instinct MI200がその代表例で、XCUのダイが735.4平方mmほど×2、HBM2Eが109.5平方mm×8で、合計で2346.8平方mm。なのでパッケージ全体では軽く3000平方mmほどになる。Silicon Interposerは、通常のチップと同じく露光→エッチングという工程で製造されるから、どんなに頑張ても800平方mmほどが寸法の上限であり、なので全体をまとめてカバーするInterposerを製造するのは、少なくともSiliconベースでは不可能である(TSMCは第二世代のCoWoS-2では、露光サイズを1.5倍に引き上げるテクニックを導入した事で最大1200平方mmまで可能とはなったが、それでもRadeon Instinct MI200には全然足りない)。
そこでSilicon Interposer(CoWoS-S)に替え、低損失の有機基板を利用したCoWoS-Rがラインナップされた(Photo05)。こちらはSilicon Interposerに比べると損失が多いといった欠点はあり、なので信号速度の上限などは低くなるが、その代わり3000平方mmの巨大なInterposerも製造可能になる、いわば低コストのソリューションである。

Photo05: CoWoS-RのRDL Interposerは6層基板構成になっている。
第3のSolutionがCoWoS-Lである。Local Si Interconnetと呼ばれる方式で、要するにチップ全体をカバーするのでなく、チップ間Interconnectが必要な個所だけにSilicon Interposerを充て、他の箇所はRDLでカバーするというやり方だ。これを応用したのがAMDがRadeon Instinct MI200で採用したElevated Fanout Bridgeである。AMDはRDL層の代わりにCu Pillerを立ててパッケージと直結する、という形にしているが、まぁ方法論としては一緒である。
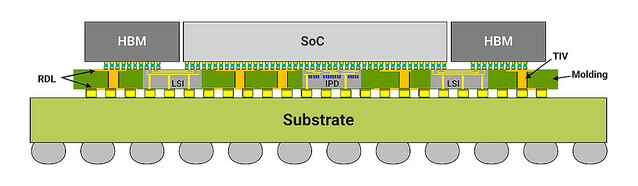
Photo06: この例ではSoCとHBMの間にLSIが入り、その他の場所には普通のRDLが入る形。SoC真下のIPDはIntegrated Passive Deviceの意味で、要するにパスコンなどが配される格好。
InFO: 主にMobile SoCに多用されている方式。要するにSoCの周囲にCu Pillerを立てて、SoCの上にDRAMを積層する(Photo07)という方式である。勿論DRAMでなくSoCを実装する事も可能であり、実際に3層とか4層構造の例もある。こちらも、途中のInterposerをSiliconベースにするか有機基板ベースにするかでINFO-LかInFo-Rかに分かれるが、構造としては同じだ。また、特にMobile向けの場合、4Gとか5Gのモデムを集積する場合があり、ノイズ対策などからこれを立体ではなく平面置きにしたいというニーズがあったことから、InFOをベースにチップを平面置きとしたInFO-oSという派生型もあるが、PC向けではそこまで統合されることは無い(5Gモデムは大体PCIe M.2モジュールの形でシステム実装であり、CPUに統合されたりはしない)ので、ここでは割愛する。
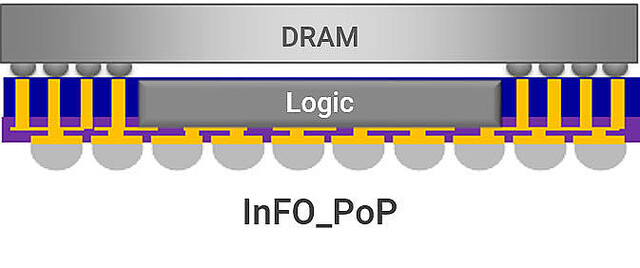
Photo07: この図ではDRAMの信号ピンが左右に寄っている様に見えるが、実際にはDRAMの真裏にくまなくピン(というか、ball)が出ているので、DRAMとPillerの間にもInterposerを挟むことが多い。
SoIC: 真の3次元実装。SoICの詳細は昨年ここで詳細に説明したので、今回は割愛する。最初の実装はAMDの3D V-Cacheである。ちなみにSoICには、その3D V-Cacheに採用されたSoIC-CoW(Chip on Wafer)以外に、ウェハのレベルでStackingを行うSoIC-WoW(Wafer on Wafer)という技術もあるとされているが、今のところ適用された事例を聞かない。今年あたり、AIチップ向けなどで出てくるのだろうか?
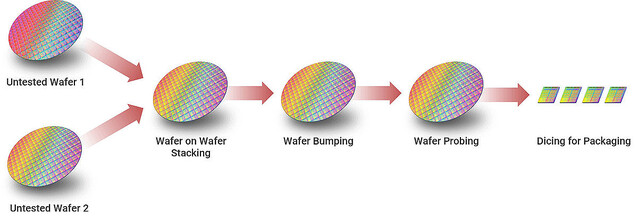
Photo08: 単にDicing(チップをWaferから切り出し)してから重ねるか、Dicing前に重ね合わせて切り出すかの違い。重ね合わせの手間がコスト増加要因になるので、SoIC-WoWにすればコストは減ることになる。ただこの場合上側と下側のチップの面積が当然同一になる訳で、3D-Vcacheの様に大きなダイの上に小さなダイを重ねる場合には向かない。
そんなわけで2022年もTSMCは大忙しである。AMDはZen 4とCNDA 2、後半にはNavi 30シリーズを投入してくるだろうし、IntelもAlchemistに加え、Alder LakeのLow end SKUをここに移すという話がある。NVIDIAもGeForce RTX 4000シリーズをTSMCの5nmにするらしいし、現在のGA100(NVIDIA A100シリーズ)の後継をTSMCに委託したいようだ。PC業界にとっては、TSMCの重要度が更に増す1年になりそうである。
●プロセス編 - 2022年のSamsung
○Samsung(Photo09)

Photo09: この写真を撮った数日後に里親さんのところに移動。その後黒白(左)は見事なナルシストに、キジ白(右)は立派な大福もちに、キジトラ(中央)はすてきなお姫様に、それぞれ成長しました。
TSMCに比べるとPC業界ではやや影が薄い(現状はNVIDIAのGeForce RTX 3000シリーズのみ)Samsungであるが、2022年は適用範囲がグンと増える予定だ。最大の理由はTSMCがOver Capacityだから、という話である。後述の様にIntelのFoundry Serviceが立ち上がるまでにはもう少し時間が掛かる以上、現時点で選択可能なのはTSMCかSamsungしかないからだ。
そのSamsungであるが、既に4nm世代までの量産に入っており、いよいよ今年はGAA(Gate All Around)を採用した3GAAの量産がスタートする(Photo10)。ということで、まずはSamsungのラインナップを改めてご紹介するとこんな感じになる(Photo11)。

Photo10: 大まかなSamsungのロードマップ。とりあえずSamsungがGAA一番乗りは間違いなさそうだ。

Photo11: 詳細ロードマップ。3GAPと2GAPの間がちょっと空くあたり、間に何か追加される可能性もある。
順に説明すると
7LPP(7nm Low Power Plus) : 7nm世代の基本。EUV露光を利用する最初のプロセス。既に量産中。
6LPP(6nm Low Power Plus) : 7LPPの改良版。SDB(Single Diffusion Block)を利用する事でトランジスタ密度を向上させている。また7LPPと比較して消費電力効率を向上させているという説明であった。ただ性能に関しては変わらない模様。
5LPE(5nm Low Power Early) : 6LPPをベースにしながら、性能向上(7LPP比で11%)とエリアサイズ削減(同30%)、消費電力削減(同20%)を実現したもの。もっともエリアサイズに関しては(以前ここでも説明したが)Cell Libraryの変更(7.5T→6T)とかCNT near Active Gateなどが搭載される。このCNT(Contact) near Active Gateとは、トランジスタ層とその上の配線層への接続(Contact)を、回路のすぐそばに置くことでエリアサイズを縮小する技術。これを更に進めたのが次の4LPEで採用されるCNT over Active Gate(回路の真上にContactを配する)で、更にエリアサイズが小さくなる。IntelだとこれをCOAGと呼んでいるが、そもそもIntelの10nmが立ち上がらなかった理由の一つがこのCOAGの実装が大変だった、という話でもある。SamsungはいきなりCOAGをぶっこむのではなく、5nmではゲートとContactの位置を非常に接近させ、4nmでやっとCOAGを実装した格好だ。このあたりの慎重さは、TSMCに通じるものがある。
5LPP(5nm Low Power Plus) : 5LPEの高速版とされるが、どの程度性能が上がったのか今一つはっきりしない。一応Samsungによれば、より低い電圧でより動作周波数が引き上げられる、としている(Photo12)。QualcommがSnapdragon 888をこのSamsung 5LPPで製造を行っている。またにUHD SRAM(高密度SRAM)も利用可能になっており、大容量L3などの実装が容易になったようだ。

Photo12: 横軸が電圧、縦軸が動作周波数であるが、数字も目盛りもないので実際に何%程度向上しているのかがいまいち判断できない。
4LPE(4nm Low Power Early) : 5LPEの高密度版とでもいうべきもの。上で説明したCOAGのほか、メタルピッチの縮小でエリアサイズ縮小に伴うトランジスタ数増加を狙ったもの。
4LPE(4nm Low Power Early) : 5LPEの高密度版とでもいうべきもの。上で説明したCOAGのほか、メタルピッチの縮小でエリアサイズ縮小に伴うトランジスタ数増加を狙ったもの。AMDがこの4LPEを利用してAPUを製造するという話も出ており、もし実現すると2022年後半に市場投入の可能性がある。
4LPP(4nm Low Power Plus) : 4LPEの高速版。具体的に何をどうやって高速化するかとか、どの程度高速化されるのかといった数字が出てこないので何とも言いにくいものではあるが。ただSamsungとしては最後のFinFETプロセスである。ちなみに以前の記事では4LPPは2022年に量産スタートという話であったが、このスライドが示されたSamsung Foundry Forum 2021(2021年10月開催)の段階では既に4LPPがAvailableになっているというのは、少し予定が前倒しになったのかもしれない。
3GAE(3nm GAA Early) : GAAというかMBCFETの最初のプロセス。以前のロードマップでは4nm世代でGAAを利用する予定であったが、その後3nmに移行したという話はこちらで触れている。昨年のロードマップでも触れたが、そのGAEを当初は2021年中に投入という話だったのが少し後退している。加えて言うと、この3GAE、プロセスとしては存在するが、これを顧客向けに本当に提供するのかはちょっと疑わしい。というのは社内での評価用に製造は行うが、顧客向けには次の3GAPから提供という話が出ているためである。GAAという前例のない構造であり、競合であるTSMCやIntelは2024〜2025年にGAAを導入となっているから、3GAEをスキップしても、次の3GAAが2023年から出れば十分競争力があると言える。
3GAP(3nm GAA Plus) : というわけで最初のGAA量産プロセスではないかと言われているのがこの3GAP。性能などについては後述する。
2GAP(2nm GAA Plus) : 今回初登場のプロセスである。丁度Intel 18Aと同じタイミングであるが、こちらの詳細は不明である。
といった感じになっている。
さて、3GAE/3GAPについてもう少し紹介したい。そもそもGAAの構造は例えばこちらに示すように、チャネルの周囲を完全にGateで覆い被せる(というか、Gateの壁をチャネルが貫通する)ような構造にすることでリークを減らし、スイッチング速度を引き上げようというものだ。MBCFETもGAAFETもその意味では間違いなくGAAの一種で、違いはチャネルがナノワイヤかナノシートかの違いしかない。ちなみにSamsungだけでなく、Intel 20Aもやはりナノシートを積層する構造になっており、これが一般的になりそうである(TSMCはまだN2の詳細を公開していないので不明)。
まずGAAのメリットである。FinFETの場合、Finの数を増やして駆動電流を上げるが、その割に性能が上がりにくい(Photo13)。これに対し、GAA(というかMBCFET)の場合、シートの数にほぼ比例する様に動作周波数が上がるとする(Photo14)。またチャネルの抵抗も、GAAにすることで減らすことが可能になるとしている(Photo15)。またここには書かれていないが、FinFETの場合Finの数を増やす事になるから、その分トランジスタの横幅が増え、つまりエリアサイズが大きくなる。ところがGAAだと縦方向に積み上げられるから、いくら積んでも底面積は増えない。つまり高密度の実装が可能になる事もメリットの一つである。

Photo13: Finを3枚に増やすと駆動電流は2.2倍になるが、動作周波数は1.3倍にしかならない。
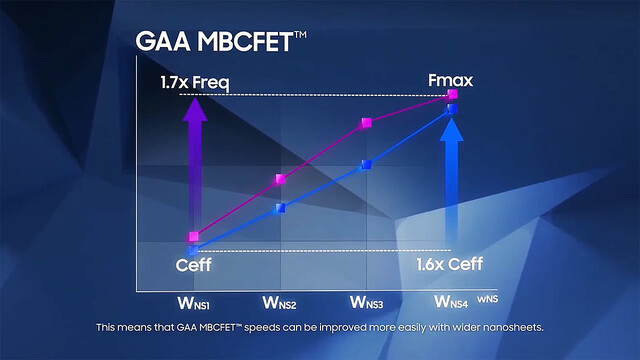
Photo14: シートを4枚にすると駆動電流は1.6倍に、動作周波数は1.7倍に向上するとする。
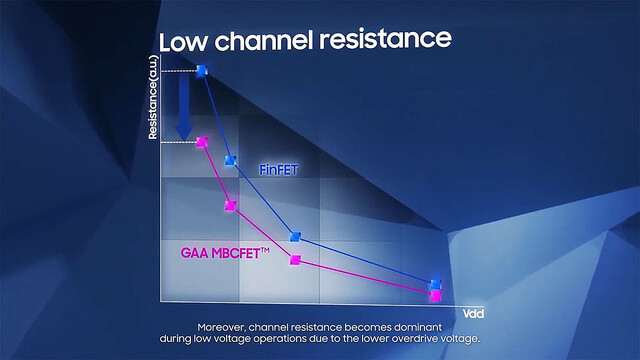
Photo15: 当たり前であるが、これはオン抵抗値の話である。
ここからは実際のプロセスの話(おそらく3GAEのものだろう)だが、まずSpeed Yieldは順調に上がっているとしており(Photo16)、またYueldそのものも順調に上がっている(Photo17)としている。実際に量産に入るにはまだ時間が掛かるだろうが、今のところは2023年の量産サービス提供に向けて順調であることをアピールした。
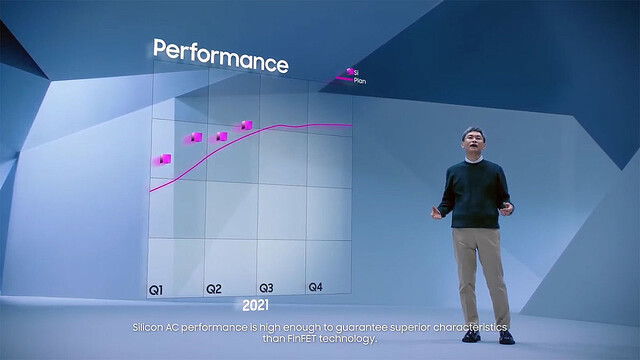
Photo16: 予定を上回るSpeed Yieldを実現できているとしている。予定ならそろそろ目標のSpeed Yieldを実現できている「筈」。

Photo17: 4LPEに比べても悪くないペースでDefectが減っている、とする。
ちなみにその次の2GAPであるが、Logic Densityはそこそこの向上で、ただし性能(というか、トランジスタの駆動電流)を大きく引き上げる方向に舵を切っている様だ(Photo18)。ちなみにPhoto19を見ると、まるでシートの数を1枚増やした(3GAPはナノシートが3枚までの様だ)のが2GAPの様に見えるが、実際にはシートの寸法も小型化されているものと思われる。

Photo18: もう昨今ではLogic Densityに関してはトランジスタよりもむしろ配線層の構成が支配的になっているので、そうそう引き上げるのは難しいとは思うが、それでも4LPE→3GAAの時と同程度には向上する見込みとされる。
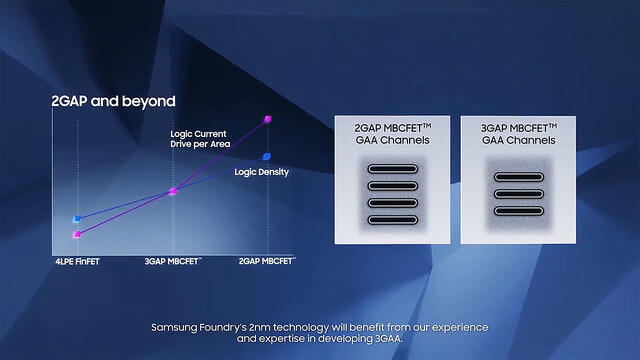
Photo19: なんというか、Photo18以上の情報が何もないスライドである。
ついでにPackagingに関してもご紹介しておきたい。TSMC及びIntelに比べると、正直言って現状のSamsungのラインナップはちょっと遅れをとっている。既に3D Stacking Solutionを提供しているといってもそれはチップ内部に留まっており(Photo21)、複数チップの統合に関してはSilicon Interposerベースの2.5Dに留まっている(Photo22)。ただ今後搭載できるHBMの数を2022年末には8つまで増やすとしている。もっと長期的に言えば、Samsungも当然3D Stackingの方向を示しており(Photo23)、まず最初に現在のX-Cubeをベースに、丁度TSMCのInFO的な3D Stacking Solutionを開発中としている(Photo24)。

Photo20: ISOCELLは同社のCMOSイメージセンサで背面透過型センサーにISPを組み合わせたもの。HBM2は内部でTSVを使って積層しているという話である。

Photo21: 当初はHBMが2つのI-Cube 2のみで、昨年4つ搭載できるI-Cube 4が量産に入った。
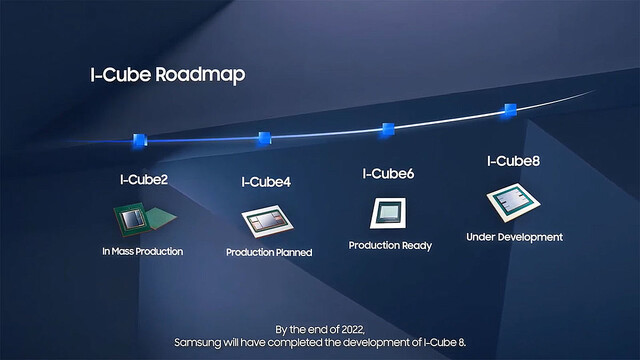
Photo22: I-Cube 6は量産準備は出来ているが、顧客がついていない。I-Cube 4はこれを利用した製品を設計中という話。
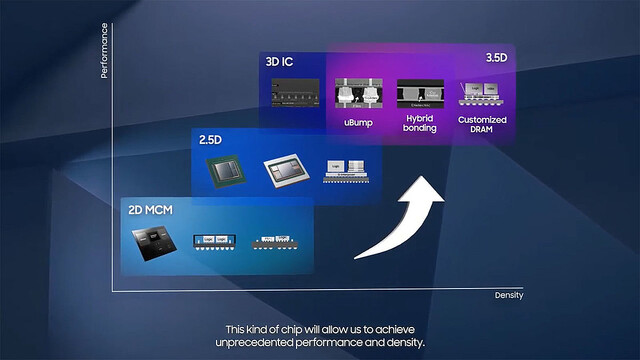
Photo23: まぁ3D Stackingに行くのは当然である。

Photo24: 小型のBase Chipの周囲にTSVを立て、Daughter Chipを搭載するという方式。
Chip-on-Chipに関しては、2020年のHotChipsで発表されたSaint-S(Photo25)が説明されたが、これ見かけはSoICと似ている。ただ実際にはSoIC(というか、AMDの3D V-Cache)とは異なり、L3そのものを拡張するというよりは、SRAMダイをL4的に接続するといったI/Fになっており、まだ量産向けとするには厳しい感じである。長期的には実装オプションの一つとして提供されるかもしれないが、短期的にはこれを利用した製品は出てこなそうだ。

Photo25: そもそも発表もHotChips 32のPoster Sessionというあたり、まだ量産向けの技術の発表とは言い難い。
なおX-Cubeに関しては、2021年11月にInterposerをSiliconではなく有機基板に切り替えたH-Cubeの提供を発表している(Photo26)。要するにCoWoS-LのSamsungバージョンと考えれば良いだろう。
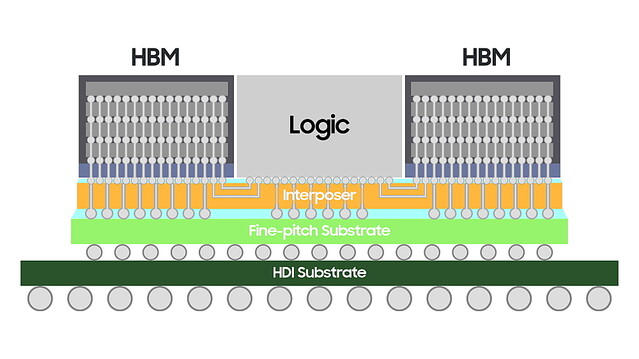
Photo26: Silicon Interposerに替えてHDI(High-Density Interconnection) substrateを利用する事で、大型のパッケージにも対応できるようになるとしている。
ということで話を戻す。GAAに関しては2023年以降なので、2022年はFinFETベースとなるが、上でちょっと書いたようにAMDはChromebook向けのAPUをSamsungの4LPEないし4LPPで製造するという話が出ている。TSMCの5nmは高価格帯向けのZen 4(や後追いでZen 4e)の製造で逼迫しているから、相対的にキャパがあるSamsungに逃がす、というあたりだろう。このマーケットも、ArmベースのSoCと競合するから、古いプロセスのままでは競争力が足りないという判断であろう。またAthlonについてもSamsungを利用するという話がある。
GPUに関しては、メインストリーム以上はNVIDIA/AMD/Intelに関しては全部TSMCの5/6nmに移行すると見られるが、例えばNVIDIAのGeForce RTX 4000シリーズのローエンドに関しては、やはりTSMCのキャパシティの問題からSamsungを使う可能性は結構高い様に思われる。
●プロセス編 - 2022年のIntel
○Intel(Photo20)

Photo27: 成長後の3匹(4歳の頃:里親さんのところでの撮影)。
Intelのプロセスに関しては昨年のこちらの記事で説明した以上の話は特になく、また同社のパッケージ技術であるEMIB/Foverosについてもこちらで説明した話以上の事が今のところ出て来ていないので、あらたまって説明する事もあまりないのだが、「以上終わり」というのもアレなので、ちょっとご紹介しておきたい。
まず現状だが、10nm(10nm SuperFin)に加えてIntel 7、旧10nm Enhanced SuperFinを利用したAlder Lakeが無事に出荷開始された。無駄に長い評価記事はともかくとして、その後で掲載させていただいた、同じく無駄に長いDeep Diveの最後の方で、動作周波数と消費電力の関係を示したグラフを掲載させていただいた。このグラフを見る限り、14nm++(14nm+++という話もあるが、まぁ公式には14nm++である)と比較して、確かに消費電力そのものはきちんと下がっている。ただし動作周波数の上限は14nm++と大して変わらない。結果Intel 7のIntel 14nm++に対するメリットは、トランジスタ密度と消費電力削減だけであって、動作周波数向上は果たせなかったということになる。もっとも、トランジスタ密度が上げられるという事はそれだけ複雑なダイを突っ込めるという事でもあり、事実Alder Lakeではピーク6命令解釈・実行のGolden Coveコアを導入してIPCを引き上げる事で、性能向上に成功している。その意味ではIntel 7の目的は果たせたのだろうが、逆に言うとIntel 10nm(10nm SuperFin)はIntel 7ほどに動作周波数が上がらなかったという事であり、なるほどDesktop向けに導入できなかったのも理解できる。
その次はIntel 4である。これは同社初のEUV露光を利用したプロセスであり、2023年前半に量産開始とされている。ただ2023年前半に量産開始、ということは製品が出てくるのは早くて2023年第2四半期末、実際には2023年第3四半期中か第4四半期初めというあたりではないかと思われる。ただしこれはIntelのスケジュール通りに進めば、という但し書き付きの話。2021年12月のIEDMでIntelは"2025年以降もMooreの法則を維持するためのブレークスルー"と題した発表を行っているが、肝心のIntel 4に関しての発表が皆無、というあたりは非常に微妙なものを感じざるを得ない。Meteor Lakeは2022年第1四半期にTape inするという話なので、間もなく物理設計が始まる予定だが、本当に予定通り出てくるかどうかは神のみぞ知る、という状況である。時期的にはまさにこの原稿が公開されている今、Intel 4を使ってMeteor Lakeを作るか、それともTSMCのN5 or N4Pあたりを使って作るかの決断が下されるわけで、この後IntelがMeteor Lakeについての説明が変わらないか否か、である程度Intel 4の動向が見えてきそうである。
Intel 3は、順調にIntel 4が立ち上がれば、半年かそこら遅れで利用可能になると見られている。これは元々7nm++として位置づけられていたもので、その意味ではIntel 4+とでもいうべきものだから、Intel 4さえ順調ならこちらはそれほど提供に支障はないだろう。逆にIntel 4がコケると、こちらも順延ないしスキップされる可能性もある。もっともその先にはもっと難易度の高いGAAが待ち構えているので、結果的にはIntel 4が遅れてもIntel 3も提供されることになるかもしれない。
Intel 20Aは2024年前半に提供開始、となっているが実験室レベルはともかくとしてこれをIntelが問題なく量産できる、と信じるにはあまりに情報が無さすぎる。SamsungがSpeed YieldとかYieldを示した(Photo16,17)のとは好対照と言わざるを得ない。
Intel 18Aは、Samsungの2GAE同様に2025年の提供となっている。まぁこれはそもそもIntel 20Aが無事に立ち上がる前提の話だし、その大前提としてEUV露光をちゃんと利用できるようになっているのか? という問題がある(今回説明では省いたが、SamsungはSFF 2021でEUVに関する細かい動向もきちんと説明しており、既に2021年の時点で全体の1/4がEUV露光を利用していると説明している)。とりあえず2022年はまだIntel 7のままなので、あとはIntel 4がどうなるか次第であろう。
もしIntel 4がまた遅れるようだと、IntelのFoundry Businessは立ち直れないくらいのダメージを受けかねない。単に製品戦略だけでなく、Gensinger CEOの下でIntel 4や3、その先のIntel 20A/18Aまで順調に進むことを前提に、猛烈な規模でFabを増設して生産能力を高めるべく莫大な投資を行っているからで、これの回収が出来なくなる恐れすらあるためだ。
話を戻すと、そんなわけで2022年中に出てくる、Intelのプロセスを利用する製品は、Intel 7ベースのものだけである。次のCPU編で詳しく触れるが、Alder LakeとMeteor Lakeの間にRaptor Lakeという製品が入るのは多分間違いないが、このRaptor LakeはTSMC N3になるという話である。これに先立ち、一部の製品がTSMC N5に切り替わるとされている。噂ではCore i3グレード以下となっていたが、Pentium/Celeronのみという話もあり、どちらが正解か現時点ではちょっと判断できない。これはMobile向けも同じである。
Server向けは、今年Sapphire Rapidsが導入されるが、これはIntel 7ベースとなる模様。ただGPUに関しては先に書いたようにTSMC N6ベースとなる。なかなかハイブリッドな状況になるようだ。
2022年の幕開けに、パーソナルコンピュータのハードウェア技術の動向を占う「PCテクノロジートレンド」をお届けする。まずは業界のあらゆる活動に大きな影響を及ぼす半導体プロセスの動向について紹介したい。
***
皆様、あけましておめでとうございます。本年もよろしくお願いします。
2020〜2021年はコロナに明け暮れた感もあるが、引き続きオミクロン株が猛威を振るっており、まだこの先の動向がどうなるかは判らない。もっとも企業としても、その辺りを勘案しながらビジネスを進めており、その意味ではコロナを気にしつつも製品は投入され続けているわけで、今年も色々動きがありそうである。という事で何時もの通り、今年の予測などを。まずはProcess関連の動きから(Photo01)。
○TSMC(Photo01)
ご存じの通り現時点では業界最大かつ業界最先端の製造能力を持つTSMC。PC業界で言ってもIntel、AMD、NVIDIA(PC向けはまだSamsung:HPC向けがTSMC)がTSMCに委託または委託予定、というあたりで何をかいわんやである。
2021年は熊本に新工場を作るという話になっているが、こちらは産業向けがメインとなる28/22nmノードである。ただそれ以前にアリゾナに新Fab(Fab 24)を建設予定であり、しかも当初はMegaFab(ウェハ生産量が300mm換算で月産25000枚程度)という話だったのが、いつの間にかそれが6棟に増え、GigaFab(同月産10万枚以上)に昇格しているという騒ぎである。またここに後工程工場を追加するという報道も出てきており、これが実現するとちょっとした規模の生産拠点となる。
といっても、TSMCは既に台湾にGigaFabを5つ(Fab 3/6/12/15/18)持っており、今後Fab 18の増強(Phase 3〜6:2022年中に稼働)とFab 20(2024〜2025年に稼働予定)が予定されているから、メインは引き続き台湾ということになる。なおFab 24の稼働予定は2024年という話なので、少なくとも現時点では考慮しても仕方ないところである。
なお先端プロセスに関しては、7nm世代がFab 15、5nmがFab 18のPhase 1〜3、3nmがFab 18 Phase 4〜6(7もある、という話も出ている)、2nmがFab 20の予定である。Fab 21は5nmという話だが、ひょっとすると3nmになるかもしれない。
さてそのTSMCであるが、更にプロセスが複雑化している。一覧で示すと
N7 : TSMCの最初の7nmプロセス。ArF液浸+マルチパターニング。TSMCによれば昨年7月の時点で既に10億個のN7ベースのチップが出荷されたとしている。
N7P : N7の性能向上型。N7とプロセス互換性があるため、N7の設計そのままで移行可能。ArF液浸+マルチパターニング。AppleがA13でN7Pを採用したが、性能向上率はN7比で7%(もしくは同一性能で10%の消費電力減)とそれほど大きくない。
N7+ : N7の製造プロセスの一部(トランジスタ層と一部の配線層)をEUV露光に切り替えたもの。N7と設計の互換性がないので、N7からそのままの移行はできない。そのあたりもあって、あまり多くのチップでは採用されていない。
N6 : N7の一部をEUV化したという意味ではN7+に近いが、N7+との最大の違いはN7と設計の互換性があること。N7あるいはN7Pを利用していたデザインはそのままN6に移行可能とされる。またN7+よりEUV露光を使う配線層が1層多い。2020年から量産を開始しており、2021年末では7nm世代の凡そ半分がこのN6に移行している。
N5 : 7nm世代とは全く互換性の無い新ノード。露光はEUV。こちらも2020年から量産を開始しており、現時点では最新のプロセスノードとなっている。
N4 : 2021年中にRisk Productionがスタートしており、2022年中に量産をスタートする予定だが、意図的にかどうかは知らないが性能などについては語られていない。ただ後述するN4Pの数値から算出すると、N4はN5比で4.7%の性能向上が期待できるとなり、大きくは上がらないといったところか。またN5比でマスクを幾つか減らせる、と説明されているのでおそらくはより配線層へのEUV適用が進んだものと思われる。また設計ルールやSpice(動作のアナログシミュレーション)、IPの互換性を保つと説明されている。ここから見るに、設計そのものは若干の手直しが必要で、N5向けに設計したチップをそのままN4に持ってゆく訳には行かないようだ。またトランジスタ密度そのものはN5と同等と思われる。
N4P : 2021年10月に発表された、N4の改良版。N5と比較して性能を11%改善できるほか、消費電力効率とトランジスタ密度をそれぞれ22%/6%向上させられると説明されている。ちなみにN4比では性能が6%改善となっている。設計そのものはN5/N4と互換性は無いが、容易に移行可能と説明されており、最初のN4PのTape outは2022年後半と説明されている。ということは量産シリコンが出てくるのは早くても2023年前半期と予想される。
N4X : 2021年12月に発表されたN4Pの高性能特化版。N4PはHPCからMobileまで、つまり高性能寄りにも低消費電力寄りにも出来る汎用向けプロセスであったが、N4XはHPCに特化する、つまり性能を上げる事を目的としたカスタム版である。具体的にはCPUとかGPU、それとCloud AI向けプロセッサなどで利用される形で、Mobile向けSoCでの採用は無いだろう(Apple M2以降での採用は微妙なところだが)。そのN4X、1.2V動作の場合にN5比で15%、N4P比でも4%の性能向上が期待でき、1.2Vを超える電圧だと更に性能向上が得られると説明している。またN4XはN5と同じデザインルールでの設計が可能である。つまりN5を使って製造されたCPUとかGPUのプロセスアップグレードパス、として提供される模様だ。もっともその分消費電力はかなりひどいことになりそうだし、トランジスタ密度向上は期待でき無そうである。このN4X、2023年前半にRisk Production開始とされているので、量産開始は早くても2023年末、現実問題としては2024年になりそうである。
N3 : こちらもN7→N5と同様に、5nm世代とは全く互換性の無いノードである。そしてTSMCはSamsungと異なり、この世代でもトランジスタ構造はFinFETのままである。さて、このN3であるが当初発表ではN5比でトランジスタ密度が1.7倍、性能向上が10〜15%の予定とされていた。ところが2021年10月に行われたTSMC 2021 Online Open Innovation Platform Ecosystem Forumにおける説明では、トランジスタ密度が1.6倍、性能向上が11%となり、その代わり消費電力は27%削減と説明されている(Photo02)。またこのN3にはHPC向けの構成であるN3 HPCと、更にこれに対してDTCO(Design Technology Co-Optimization:設計・製造協調最適化)を施したN3 HPC+DTCOの場合の性能も示されており、例えば0.9V動作ならN3と比較しても最大12%高速化できるとしている(Photo03)。
このN3、こちらでも触れられているが、2021年中にRisk Productionがスタートしており、2022年第2四半期あたりに量産がスタートする、とされている。ただなにしろ当初はそれほどスループットが高くない(なにしろ生産拠点であるFab 18 Phase 4〜6は現時点ではまだ完成しておらず、完成して製造設備がフル稼働状態になるまでには軽く1年は掛かるだろう)と予測され、しかも当初はほぼ全量Appleが持ってゆく。なので、Apple「以外」の量産に入るのは2023年以降になると予測される。なので2023〜2024年はN5/N4P/N4X/N3が入り乱れる格好で量産が行われることになりそうだ。このN3もまた奪い合いになりそうではある。
N2 : TSMC初のGAAを利用するノードである。こちらは2024年以降の量産開始(当初は2025年という話だったが、これを前倒ししているという話も出ている)なので、Risk Productionは早くても2023年後半とかになるだろう。こちらに関してはまだ「やる」という以上の情報が出てきていないのが正直なところである。
といった具合になっている。また、今のところは一切情報は無いが、過去の経緯で考えるとN3とN2の間にもう一つ二つ、プロセスが挟まっても不思議ではない。N3PなりN3Xなりが後追いで追加され、2023年後半〜2024年に量産開始、という事になりそうな気もする。
さてこのTSMCのプロセス、スマートフォン向けSoCやAIプロセッサ向けに奪い合いが始まっている訳だが、当然PC向けにも奪い合いが始まっている。詳しくは後述するが、比較的確実と見られているだけで
N6: Intel Alchemist、AMD Navi 24、AMD Zen 4 IOD、AMD CDNA 2.0
N5: AMD Navi 31?、NVIDIA GA200?、AMD Zen 4 CCD、Intel Alder Lake
N3: AMD Zen 5 CCD、Intel Raptor Lake GPU、NVIDIA GA300?
辺りがぱっと出てきて、恐らく今後は更に増えるだろう。
またTSMCはPackagingに関してもやはり進んでいる。Photo04が現在TSMCが提供しているPackaging技術の一覧である。
ここで、
CoWoS: いわゆる2.5D Stackingで、HBM/HBM2/HBM2E/HBM3などの接続は今のところこれに頼る必要があるし、GPUだけでなくAIチップや一部CPUにも利用されている(富士通のA64fxなど)。基本となるのがCoWoS-Sで、これはすべてのチップを搭載するのに必要な、大型のSilicon Substrateを製造し、この上にチップを載せる構造である。ただチップの大型化に伴い、全てのチップを載せきれるSilicon Interposerを製造するのが難しくなってきた。Radeon Instinct MI200がその代表例で、XCUのダイが735.4平方mmほど×2、HBM2Eが109.5平方mm×8で、合計で2346.8平方mm。なのでパッケージ全体では軽く3000平方mmほどになる。Silicon Interposerは、通常のチップと同じく露光→エッチングという工程で製造されるから、どんなに頑張ても800平方mmほどが寸法の上限であり、なので全体をまとめてカバーするInterposerを製造するのは、少なくともSiliconベースでは不可能である(TSMCは第二世代のCoWoS-2では、露光サイズを1.5倍に引き上げるテクニックを導入した事で最大1200平方mmまで可能とはなったが、それでもRadeon Instinct MI200には全然足りない)。
そこでSilicon Interposer(CoWoS-S)に替え、低損失の有機基板を利用したCoWoS-Rがラインナップされた(Photo05)。こちらはSilicon Interposerに比べると損失が多いといった欠点はあり、なので信号速度の上限などは低くなるが、その代わり3000平方mmの巨大なInterposerも製造可能になる、いわば低コストのソリューションである。
第3のSolutionがCoWoS-Lである。Local Si Interconnetと呼ばれる方式で、要するにチップ全体をカバーするのでなく、チップ間Interconnectが必要な個所だけにSilicon Interposerを充て、他の箇所はRDLでカバーするというやり方だ。これを応用したのがAMDがRadeon Instinct MI200で採用したElevated Fanout Bridgeである。AMDはRDL層の代わりにCu Pillerを立ててパッケージと直結する、という形にしているが、まぁ方法論としては一緒である。
InFO: 主にMobile SoCに多用されている方式。要するにSoCの周囲にCu Pillerを立てて、SoCの上にDRAMを積層する(Photo07)という方式である。勿論DRAMでなくSoCを実装する事も可能であり、実際に3層とか4層構造の例もある。こちらも、途中のInterposerをSiliconベースにするか有機基板ベースにするかでINFO-LかInFo-Rかに分かれるが、構造としては同じだ。また、特にMobile向けの場合、4Gとか5Gのモデムを集積する場合があり、ノイズ対策などからこれを立体ではなく平面置きにしたいというニーズがあったことから、InFOをベースにチップを平面置きとしたInFO-oSという派生型もあるが、PC向けではそこまで統合されることは無い(5Gモデムは大体PCIe M.2モジュールの形でシステム実装であり、CPUに統合されたりはしない)ので、ここでは割愛する。
SoIC: 真の3次元実装。SoICの詳細は昨年ここで詳細に説明したので、今回は割愛する。最初の実装はAMDの3D V-Cacheである。ちなみにSoICには、その3D V-Cacheに採用されたSoIC-CoW(Chip on Wafer)以外に、ウェハのレベルでStackingを行うSoIC-WoW(Wafer on Wafer)という技術もあるとされているが、今のところ適用された事例を聞かない。今年あたり、AIチップ向けなどで出てくるのだろうか?
そんなわけで2022年もTSMCは大忙しである。AMDはZen 4とCNDA 2、後半にはNavi 30シリーズを投入してくるだろうし、IntelもAlchemistに加え、Alder LakeのLow end SKUをここに移すという話がある。NVIDIAもGeForce RTX 4000シリーズをTSMCの5nmにするらしいし、現在のGA100(NVIDIA A100シリーズ)の後継をTSMCに委託したいようだ。PC業界にとっては、TSMCの重要度が更に増す1年になりそうである。
●プロセス編 - 2022年のSamsung
○Samsung(Photo09)
TSMCに比べるとPC業界ではやや影が薄い(現状はNVIDIAのGeForce RTX 3000シリーズのみ)Samsungであるが、2022年は適用範囲がグンと増える予定だ。最大の理由はTSMCがOver Capacityだから、という話である。後述の様にIntelのFoundry Serviceが立ち上がるまでにはもう少し時間が掛かる以上、現時点で選択可能なのはTSMCかSamsungしかないからだ。
そのSamsungであるが、既に4nm世代までの量産に入っており、いよいよ今年はGAA(Gate All Around)を採用した3GAAの量産がスタートする(Photo10)。ということで、まずはSamsungのラインナップを改めてご紹介するとこんな感じになる(Photo11)。
順に説明すると
7LPP(7nm Low Power Plus) : 7nm世代の基本。EUV露光を利用する最初のプロセス。既に量産中。
6LPP(6nm Low Power Plus) : 7LPPの改良版。SDB(Single Diffusion Block)を利用する事でトランジスタ密度を向上させている。また7LPPと比較して消費電力効率を向上させているという説明であった。ただ性能に関しては変わらない模様。
5LPE(5nm Low Power Early) : 6LPPをベースにしながら、性能向上(7LPP比で11%)とエリアサイズ削減(同30%)、消費電力削減(同20%)を実現したもの。もっともエリアサイズに関しては(以前ここでも説明したが)Cell Libraryの変更(7.5T→6T)とかCNT near Active Gateなどが搭載される。このCNT(Contact) near Active Gateとは、トランジスタ層とその上の配線層への接続(Contact)を、回路のすぐそばに置くことでエリアサイズを縮小する技術。これを更に進めたのが次の4LPEで採用されるCNT over Active Gate(回路の真上にContactを配する)で、更にエリアサイズが小さくなる。IntelだとこれをCOAGと呼んでいるが、そもそもIntelの10nmが立ち上がらなかった理由の一つがこのCOAGの実装が大変だった、という話でもある。SamsungはいきなりCOAGをぶっこむのではなく、5nmではゲートとContactの位置を非常に接近させ、4nmでやっとCOAGを実装した格好だ。このあたりの慎重さは、TSMCに通じるものがある。
5LPP(5nm Low Power Plus) : 5LPEの高速版とされるが、どの程度性能が上がったのか今一つはっきりしない。一応Samsungによれば、より低い電圧でより動作周波数が引き上げられる、としている(Photo12)。QualcommがSnapdragon 888をこのSamsung 5LPPで製造を行っている。またにUHD SRAM(高密度SRAM)も利用可能になっており、大容量L3などの実装が容易になったようだ。
4LPE(4nm Low Power Early) : 5LPEの高密度版とでもいうべきもの。上で説明したCOAGのほか、メタルピッチの縮小でエリアサイズ縮小に伴うトランジスタ数増加を狙ったもの。
4LPE(4nm Low Power Early) : 5LPEの高密度版とでもいうべきもの。上で説明したCOAGのほか、メタルピッチの縮小でエリアサイズ縮小に伴うトランジスタ数増加を狙ったもの。AMDがこの4LPEを利用してAPUを製造するという話も出ており、もし実現すると2022年後半に市場投入の可能性がある。
4LPP(4nm Low Power Plus) : 4LPEの高速版。具体的に何をどうやって高速化するかとか、どの程度高速化されるのかといった数字が出てこないので何とも言いにくいものではあるが。ただSamsungとしては最後のFinFETプロセスである。ちなみに以前の記事では4LPPは2022年に量産スタートという話であったが、このスライドが示されたSamsung Foundry Forum 2021(2021年10月開催)の段階では既に4LPPがAvailableになっているというのは、少し予定が前倒しになったのかもしれない。
3GAE(3nm GAA Early) : GAAというかMBCFETの最初のプロセス。以前のロードマップでは4nm世代でGAAを利用する予定であったが、その後3nmに移行したという話はこちらで触れている。昨年のロードマップでも触れたが、そのGAEを当初は2021年中に投入という話だったのが少し後退している。加えて言うと、この3GAE、プロセスとしては存在するが、これを顧客向けに本当に提供するのかはちょっと疑わしい。というのは社内での評価用に製造は行うが、顧客向けには次の3GAPから提供という話が出ているためである。GAAという前例のない構造であり、競合であるTSMCやIntelは2024〜2025年にGAAを導入となっているから、3GAEをスキップしても、次の3GAAが2023年から出れば十分競争力があると言える。
3GAP(3nm GAA Plus) : というわけで最初のGAA量産プロセスではないかと言われているのがこの3GAP。性能などについては後述する。
2GAP(2nm GAA Plus) : 今回初登場のプロセスである。丁度Intel 18Aと同じタイミングであるが、こちらの詳細は不明である。
といった感じになっている。
さて、3GAE/3GAPについてもう少し紹介したい。そもそもGAAの構造は例えばこちらに示すように、チャネルの周囲を完全にGateで覆い被せる(というか、Gateの壁をチャネルが貫通する)ような構造にすることでリークを減らし、スイッチング速度を引き上げようというものだ。MBCFETもGAAFETもその意味では間違いなくGAAの一種で、違いはチャネルがナノワイヤかナノシートかの違いしかない。ちなみにSamsungだけでなく、Intel 20Aもやはりナノシートを積層する構造になっており、これが一般的になりそうである(TSMCはまだN2の詳細を公開していないので不明)。
まずGAAのメリットである。FinFETの場合、Finの数を増やして駆動電流を上げるが、その割に性能が上がりにくい(Photo13)。これに対し、GAA(というかMBCFET)の場合、シートの数にほぼ比例する様に動作周波数が上がるとする(Photo14)。またチャネルの抵抗も、GAAにすることで減らすことが可能になるとしている(Photo15)。またここには書かれていないが、FinFETの場合Finの数を増やす事になるから、その分トランジスタの横幅が増え、つまりエリアサイズが大きくなる。ところがGAAだと縦方向に積み上げられるから、いくら積んでも底面積は増えない。つまり高密度の実装が可能になる事もメリットの一つである。
ここからは実際のプロセスの話(おそらく3GAEのものだろう)だが、まずSpeed Yieldは順調に上がっているとしており(Photo16)、またYueldそのものも順調に上がっている(Photo17)としている。実際に量産に入るにはまだ時間が掛かるだろうが、今のところは2023年の量産サービス提供に向けて順調であることをアピールした。
ちなみにその次の2GAPであるが、Logic Densityはそこそこの向上で、ただし性能(というか、トランジスタの駆動電流)を大きく引き上げる方向に舵を切っている様だ(Photo18)。ちなみにPhoto19を見ると、まるでシートの数を1枚増やした(3GAPはナノシートが3枚までの様だ)のが2GAPの様に見えるが、実際にはシートの寸法も小型化されているものと思われる。
ついでにPackagingに関してもご紹介しておきたい。TSMC及びIntelに比べると、正直言って現状のSamsungのラインナップはちょっと遅れをとっている。既に3D Stacking Solutionを提供しているといってもそれはチップ内部に留まっており(Photo21)、複数チップの統合に関してはSilicon Interposerベースの2.5Dに留まっている(Photo22)。ただ今後搭載できるHBMの数を2022年末には8つまで増やすとしている。もっと長期的に言えば、Samsungも当然3D Stackingの方向を示しており(Photo23)、まず最初に現在のX-Cubeをベースに、丁度TSMCのInFO的な3D Stacking Solutionを開発中としている(Photo24)。
Chip-on-Chipに関しては、2020年のHotChipsで発表されたSaint-S(Photo25)が説明されたが、これ見かけはSoICと似ている。ただ実際にはSoIC(というか、AMDの3D V-Cache)とは異なり、L3そのものを拡張するというよりは、SRAMダイをL4的に接続するといったI/Fになっており、まだ量産向けとするには厳しい感じである。長期的には実装オプションの一つとして提供されるかもしれないが、短期的にはこれを利用した製品は出てこなそうだ。
なおX-Cubeに関しては、2021年11月にInterposerをSiliconではなく有機基板に切り替えたH-Cubeの提供を発表している(Photo26)。要するにCoWoS-LのSamsungバージョンと考えれば良いだろう。
ということで話を戻す。GAAに関しては2023年以降なので、2022年はFinFETベースとなるが、上でちょっと書いたようにAMDはChromebook向けのAPUをSamsungの4LPEないし4LPPで製造するという話が出ている。TSMCの5nmは高価格帯向けのZen 4(や後追いでZen 4e)の製造で逼迫しているから、相対的にキャパがあるSamsungに逃がす、というあたりだろう。このマーケットも、ArmベースのSoCと競合するから、古いプロセスのままでは競争力が足りないという判断であろう。またAthlonについてもSamsungを利用するという話がある。
GPUに関しては、メインストリーム以上はNVIDIA/AMD/Intelに関しては全部TSMCの5/6nmに移行すると見られるが、例えばNVIDIAのGeForce RTX 4000シリーズのローエンドに関しては、やはりTSMCのキャパシティの問題からSamsungを使う可能性は結構高い様に思われる。
●プロセス編 - 2022年のIntel
○Intel(Photo20)
Intelのプロセスに関しては昨年のこちらの記事で説明した以上の話は特になく、また同社のパッケージ技術であるEMIB/Foverosについてもこちらで説明した話以上の事が今のところ出て来ていないので、あらたまって説明する事もあまりないのだが、「以上終わり」というのもアレなので、ちょっとご紹介しておきたい。
まず現状だが、10nm(10nm SuperFin)に加えてIntel 7、旧10nm Enhanced SuperFinを利用したAlder Lakeが無事に出荷開始された。無駄に長い評価記事はともかくとして、その後で掲載させていただいた、同じく無駄に長いDeep Diveの最後の方で、動作周波数と消費電力の関係を示したグラフを掲載させていただいた。このグラフを見る限り、14nm++(14nm+++という話もあるが、まぁ公式には14nm++である)と比較して、確かに消費電力そのものはきちんと下がっている。ただし動作周波数の上限は14nm++と大して変わらない。結果Intel 7のIntel 14nm++に対するメリットは、トランジスタ密度と消費電力削減だけであって、動作周波数向上は果たせなかったということになる。もっとも、トランジスタ密度が上げられるという事はそれだけ複雑なダイを突っ込めるという事でもあり、事実Alder Lakeではピーク6命令解釈・実行のGolden Coveコアを導入してIPCを引き上げる事で、性能向上に成功している。その意味ではIntel 7の目的は果たせたのだろうが、逆に言うとIntel 10nm(10nm SuperFin)はIntel 7ほどに動作周波数が上がらなかったという事であり、なるほどDesktop向けに導入できなかったのも理解できる。
その次はIntel 4である。これは同社初のEUV露光を利用したプロセスであり、2023年前半に量産開始とされている。ただ2023年前半に量産開始、ということは製品が出てくるのは早くて2023年第2四半期末、実際には2023年第3四半期中か第4四半期初めというあたりではないかと思われる。ただしこれはIntelのスケジュール通りに進めば、という但し書き付きの話。2021年12月のIEDMでIntelは"2025年以降もMooreの法則を維持するためのブレークスルー"と題した発表を行っているが、肝心のIntel 4に関しての発表が皆無、というあたりは非常に微妙なものを感じざるを得ない。Meteor Lakeは2022年第1四半期にTape inするという話なので、間もなく物理設計が始まる予定だが、本当に予定通り出てくるかどうかは神のみぞ知る、という状況である。時期的にはまさにこの原稿が公開されている今、Intel 4を使ってMeteor Lakeを作るか、それともTSMCのN5 or N4Pあたりを使って作るかの決断が下されるわけで、この後IntelがMeteor Lakeについての説明が変わらないか否か、である程度Intel 4の動向が見えてきそうである。
Intel 3は、順調にIntel 4が立ち上がれば、半年かそこら遅れで利用可能になると見られている。これは元々7nm++として位置づけられていたもので、その意味ではIntel 4+とでもいうべきものだから、Intel 4さえ順調ならこちらはそれほど提供に支障はないだろう。逆にIntel 4がコケると、こちらも順延ないしスキップされる可能性もある。もっともその先にはもっと難易度の高いGAAが待ち構えているので、結果的にはIntel 4が遅れてもIntel 3も提供されることになるかもしれない。
Intel 20Aは2024年前半に提供開始、となっているが実験室レベルはともかくとしてこれをIntelが問題なく量産できる、と信じるにはあまりに情報が無さすぎる。SamsungがSpeed YieldとかYieldを示した(Photo16,17)のとは好対照と言わざるを得ない。
Intel 18Aは、Samsungの2GAE同様に2025年の提供となっている。まぁこれはそもそもIntel 20Aが無事に立ち上がる前提の話だし、その大前提としてEUV露光をちゃんと利用できるようになっているのか? という問題がある(今回説明では省いたが、SamsungはSFF 2021でEUVに関する細かい動向もきちんと説明しており、既に2021年の時点で全体の1/4がEUV露光を利用していると説明している)。とりあえず2022年はまだIntel 7のままなので、あとはIntel 4がどうなるか次第であろう。
もしIntel 4がまた遅れるようだと、IntelのFoundry Businessは立ち直れないくらいのダメージを受けかねない。単に製品戦略だけでなく、Gensinger CEOの下でIntel 4や3、その先のIntel 20A/18Aまで順調に進むことを前提に、猛烈な規模でFabを増設して生産能力を高めるべく莫大な投資を行っているからで、これの回収が出来なくなる恐れすらあるためだ。
話を戻すと、そんなわけで2022年中に出てくる、Intelのプロセスを利用する製品は、Intel 7ベースのものだけである。次のCPU編で詳しく触れるが、Alder LakeとMeteor Lakeの間にRaptor Lakeという製品が入るのは多分間違いないが、このRaptor LakeはTSMC N3になるという話である。これに先立ち、一部の製品がTSMC N5に切り替わるとされている。噂ではCore i3グレード以下となっていたが、Pentium/Celeronのみという話もあり、どちらが正解か現時点ではちょっと判断できない。これはMobile向けも同じである。
Server向けは、今年Sapphire Rapidsが導入されるが、これはIntel 7ベースとなる模様。ただGPUに関しては先に書いたようにTSMC N6ベースとなる。なかなかハイブリッドな状況になるようだ。





