
画像生成AI「Stable Diffusion」で崩れがちな顔をきれいにできる「GFPGAN」を簡単に使える「Stable Diffusion web UI(AUTOMATIC1111版)」の基本的な使い方


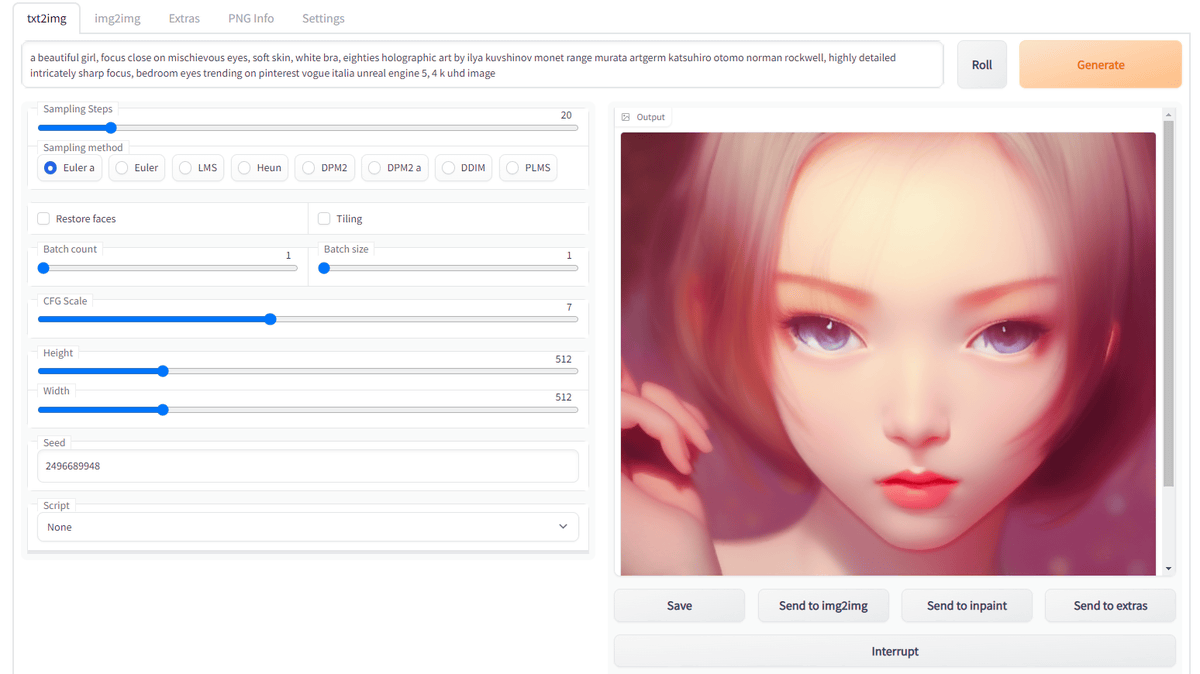
「Stable Diffusion web UI(AUTOMATIC1111版)」は他のUIには搭載されていない機能なども盛り込んだ、いわば決定版の「Stable Diffusion」のUIといえますが、それだけにやれることが多いので、どこをどう触ればよいか悩むこともあるはず。
この記事ではまず、「Stable Diffusion web UI(AUTOMATIC111版)」のうち、テキストから画像を生成する「txt2img」の基本的な使い方をまとめています。
・1:最も簡単な使い方
・2:「txt2img」タブ内の各項目はどういう意味なのか?
Stable Diffusion web UI(AUTOMATIC1111版)は画像生成AI「Stable Diffusion」を使うためのUIの1つ。Stable Diffusionの利用にはNVIDIA製GPUが必要で、該当するPCにStable Diffusion web UI(AUTOMATIC1111版)をインストールすることになりますが、Pythonを実装したウェブプラットフォーム「Google Colab」にStable Diffusionをインストールするという手を使うことで、NVIDIA製GPUなしの環境でも利用が可能です。インストール方法については以下の記事で詳しく説明しています。
画像生成AI「Stable Diffusion」を4GBのGPUでも動作OK&自分の絵柄を学習させるなどいろいろな機能を簡単にGoogle ColaboやWindowsで動かせる決定版「Stable Diffusion web UI(AUTOMATIC1111版)」インストール方法まとめ - GIGAZINE

◆1:最も簡単な使い方
「とりあえず、なにか画像を作りたい」という場合、「Prompt」の欄に出力したい画像に関連する文字列を入力して「Generate」を押せばOK。

「Prompt」が空でも一応画像は作ってくれますが、まったく指針がない状態なのではっきりとしない絵になります。

「Prompt」に何を入れればいいのかに関しては、画像がどんなプロンプトで生成されたものなのかを見られる「Lexica」などを参考にしてください。
話題の画像生成AI「Stable Diffusion」で使える呪文のような文字列を実際の画像から見つけられる「Lexica」の使い方まとめ - GIGAZINE

画像生成はデフォルト設定だと1回3秒〜10秒ほど。生成途中で止めたいときは「Interrupt」を押します。

生成した画像は、ブラウザで「名前を付けて画像を保存」しなくても、「Stable Diffusion web UI」をインストールしたフォルダの下層の「output」内に、「txt2img-grids」「txt2img-images」に分けて保存されています。

「txt2img-grids」は、1回に複数の画像生成を行ったときの画像が一覧状態となったものが保存されています。

「txt2img-images」は過去に生成した画像がすべて保存されています。

この「txt2img-images」に保存されているファイルは、名前に生成時のプロンプトが自動的に挿入されているほか、メタデータとしてシード値や生成時の設定が埋め込まれているので、同設定での画像再生成ができます。

画像に埋め込まれたメタデータをもう一度再利用したい場合は「PNG info」タブを開き、画像をドラッグ&ドロップ。

画像が表示されたら「送信」をクリック。

すると画面右側に、生成時のプロンプトやパラメーター、シード値が表示されます。

◆2:「txt2img」タブ内の各項目はどういう意味なのか?
Stable Diffusion web UI(AUTOMATIC1111版)の各項目にはポップアップヘルプが用意されていて、マウスカーソルを重ねるとどういう項目なのか表示されるのですが、内容が英語で、しかもポップアップだと文字列をコピーして翻訳できず、ページごと翻訳だと翻訳されない項目があったので、以下に情報をまとめました。
「Prompt」欄の右側にある「Roll」は画像生成用のプロンプトにランダムなアーティスト名を追加します。1回押すごとに1人追加されます。

アーティストは、「Setting」タブ内の下の方にあるカテゴリー一覧にチェックを入れると、特定カテゴリーの人を登場させることが可能。たとえば「amime」だと大友克洋や今 敏、出水ぽすかなどの名前が出ました。ただ、浮世絵師の画登軒春芝、洋画家の藤島武二といった名前も出てくるので、必ずしもアニメや漫画には限らないようです。また「c」や「n」といった謎のカテゴリーもあります。

以下はStable Diffusion web UI(AUTOMATIC1111版)の画面左側にある、画像生成前に調整する部分です。
「Sampling Steps」は、画像生成にあたってのフィードバック工程を何回行うのかということ。数を増やせば増やすほど精緻な絵になっていきますが、当然、増やすほど時間がかかるようになります。また、数を増やせばいい絵になるというものではないというのも難しいところ。初期設定の20でもそこそこに仕上がりますが、増やしたいなら目安は110ぐらいまでです。

「Sampling method」は、フィードバック工程においてどのようなアルゴリズムを採用するのかを選べます。基本的には「Euler a」でOK。

「Restore faces」と「Tiling」は、このAUTOMATIC1111版の特徴の1つでもあります。「Restore faces」はGenerative Facial Prior GAN(GFPGAN)を用いてそのままだと崩れがちな顔の補正を強力に行い、できるだけ左右対称を維持してくれます。「Tiling」は生成した画像をタイルのように並べます。

公式リポジトリに、どれぐらいの補正ができるか比較した画像があります。左端が元写真、中央の4つはその他のアルゴリズム、右端がGFPGANです。

Stable Diffusionは画像生成を「バッチ」単位で行います。バッチを何回行うのかが「Batch count」、1回のバッチで何枚の画像を生成するのかが「Batch size」です。1回に生成する画像が多いとVRAM使用量が増えるので、VRAMが少ない環境だとエラーが出やすくなります。そのため、VRAMの少ない環境だと「Batch count」で生成したい数を指定し、「Batch size」は1にしておくとエラーなく安定して画像生成ができます。

「CFG Scale」は、他のStable Diffusionのフロントエンドと同様で、プロンプトの指示にどれぐらい従うかを示す値で、大きくすればするほど指示に沿った内容になりますが、絵自体が崩れやすくなります。一般的には7〜11が適当とされています。

「Height」と「Width」は出力画像のサイズ。そもそもモデルが512×512に最適化されているため、最も高品質な画像が生成されるのは512×512です。なお、画像面積はそのままVRAMの使用量に反映されるため「512×832のちょっと縦長画像を作りたい」といった場合に、VRAMが少ないとエラーが出て生成されないことがあります。

「Seed」はシード値。「-1」だと毎回ランダム生成となります。「あの画像はうまくできたから、構図を再現したい」という場合、当該画像のシード値を入力することで、同じ構図や雰囲気を維持して、別パターンの画像を生成することができます。

「Script」はスクリプトが使用できます。デフォルトは「None」となっています。これは別途記事化予定です。

生成した画像の下部には、画像を扱うボタンが複数表示されています。「Save」だと、生成した画像をまとめて「log/images」の中にCSVファイルとともに保存します。生成された画像のうち1枚を選んで「Send to img2img」を押すと「img2img」タブに送られます。同様に「Send to inpaint」だと「img2img」タブのインペインティング機能に送られるので、画像の一部分にマスクをかけられます。「Send to extras」だと「Extras」タブに送られます。

次の記事ではスクリプトの部分を細かく見ていきます。
<つづく>





