
Hugging FaceのAIモデルをテストする「Open LLM Leaderboard v2」で中国Qwenのモデルがトップに



世界中のオープンソース言語モデルをランク付けする「Open LLM Leaderboard」のバージョン2をHugging Faceが公開しました。公開時点でトップの座に輝いたのは、アリババが開発した「Qwen2-72B-Instruct」でした。
Open-LLM performances are plateauing, let’s make the leaderboard steep again - a Hugging Face Space by open-llm-leaderboard
Chinese AI models storm Hugging Face's LLM chatbot benchmark leaderboard - Alibaba runs the board as major US competitors have worsened | Tom's Hardware
https://www.tomshardware.com/tech-industry/artificial-intelligence/chinese-llms-storm-hugging-faces-chatbot-benchmark-leaderboard-alibaba-runs-the-board-as-major-us-competitors-have-worsened
ランク付けにあたり、各言語モデルは「知能テスト」「短い文脈と長い文脈での推論」「複雑な数学能力」「人間の指示にどの程度従うのか」という4つのタスクで評価されました。
評価には、多肢選択式のベンチマーク「MMLU-Pro」、高度に専門的な知識を測る「GPQA」、殺人事件の謎を解くなどの問題がある「MuSR」、数学適性テストの「MATH」、指示に従う能力を問う「IFEval」、人間の興味を引くような答えを出すかを測る「BBH」、以上6つのベンチマークが用いられました。
7500を超えるモデルが評価され、堂々の1位となったのは「Qwen2-72B-Instruct」でした。Hugging Faceは「Qwen2-72B-Instructは他のモデルよりも頭一つ抜けています」と語っています。事実、平均評価点が40点台に到達したのはQwen2-72B-Instructのみでした。
結果は以下のリンクから確認できます。
Open LLM Leaderboard 2 - a Hugging Face Space by open-llm-leaderboard
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
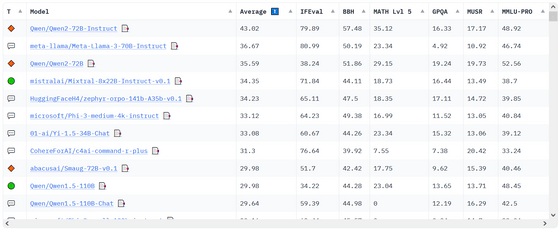
このランキングは順次変動しています。記事作成時点で、1位から10位までの内訳は以下の通りです。
1位:Qwen/Qwen2-72B-Instruct
2位:meta-llama/Meta-Llama-3-70B-Instruct
3位:Qwen/Qwen2-72B
4位:mistralai/Mixtral-8x22B-Instruct-v0.1
5位:HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1
6位:microsoft/Phi-3-medium-4k-instruct
7位:01-ai/Yi-1.5-34B-Chat
8位:CohereForAI/c4ai-command-r-plus
9位:abacusai/Smaug-72B-v0.1
10位:Qwen/Qwen1.5-110B
上記の通り、Qwenのモデルはトップ10のうち3つを占め、圧倒的な強さを見せています。なお、今回9位となった「Smaug-72B」は2024年2月時点でOpen LLM Leaderboard バージョン1のトップでした。Smaug-72Bは、今回3位の「Qwen-72B」を微調整して作られたモデルです。
Abacus AIがリリースしたオープンソースLLM「Smaug-72B」がHugging FaceのOpen LLM LeaderboardでトップとなりいくつかのベンチマークでGPT-3.5を上回ったことが明らかに - GIGAZINE






