Stability AIが画像を認識して日本語で回答してくれるAIモデル「Japanese InstructBLIP Alpha」をリリース


画像生成AI「Stable Diffusion」を開発するStability AIが、日本語向け画像言語モデル「Japanese InstructBLIP Alpha」を一般公開したと発表しました。入力した画像に対して日本語で説明を生成できる画像キャプション機能や、画像についての質問を日本語で入力すると日本語で回答する機能が搭載されています。
日本語画像言語モデル「Japanese InstructBLIP Alpha」をリリースしました - Stability AI Japan

stabilityai/japanese-instructblip-alpha · Hugging Face
https://huggingface.co/stabilityai/japanese-instructblip-alpha

「Japanese InstructBLIP Alpha」は、2023年8月に公開された日本語言語モデル「Japanese StableLM Alpha」を拡張したモデルです。
日本語言語モデル「Japanese StableLM Alpha」をStability AIがリリース - GIGAZINE

Japanese InstructBLIP Alphaはその名の通り、画像言語モデルのInstructBLIPを用いており、画像エンコーダとクエリ変換器、Japanese StableLM Alpha 7Bで構成されています。ただし、少ない日本語データセットで高性能なモデルを構築するため、英語の大規模データセットで事前学習したInstructBLIPでモデルの一部を初期化し、日本語データセットを用いてチューニングしているとのこと。
使われているトレーニング用のデータセットは以下の通り。
・画像データセット「Conceptual 12M」の日本語訳版
・画像データセット「COCO」とその日本語キャプションデータセットである「STAIR Captions」
・日本語の画像質疑応答データセット「Japanese Visual Genome VQA dataset」
例えば、以下の用に写真を読み込ませると、Output(出力)のところに「桜と東京スカイツリー」と、画像を認識した結果を日本語で回答します。

金閣寺の写真を読み込ませた場合、「京都の金閣寺」という回答を返しています。

以下の画像では、「富士山を見ながらベンチに座っている2人」と回答。単純に名詞を並べるだけではなく、写っているものの関係性を示しているのがポイント。

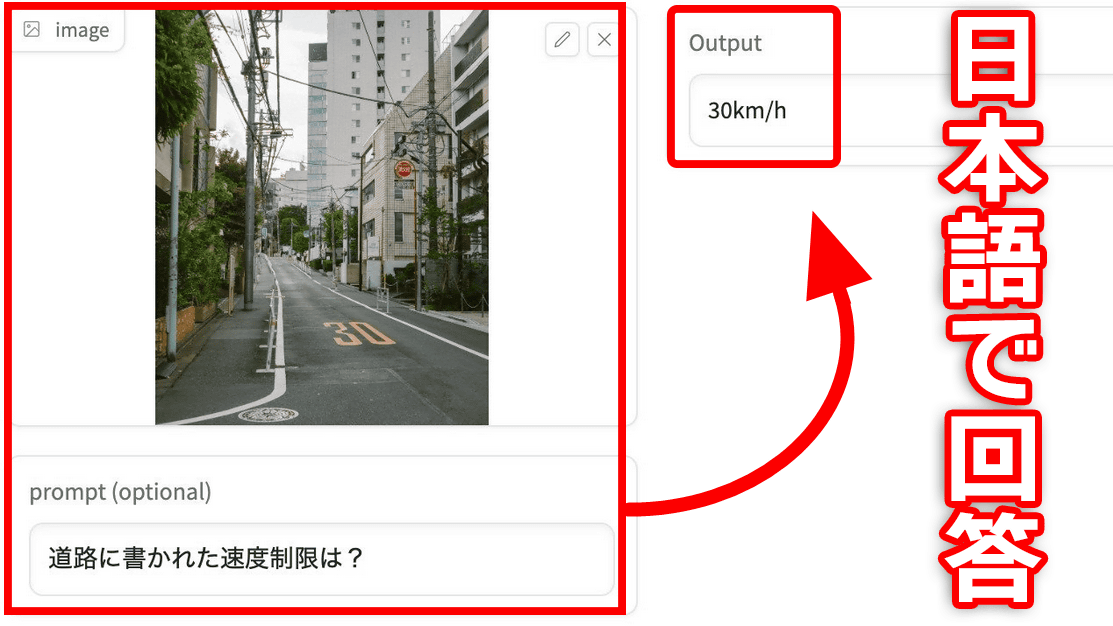
今度は街中の風景写真を読み込ませた上で、prompt(テキスト入力)で「道路に書かれた速度制限は?」と質問すると、「30km/h」と回答。

雪の中で2つ並ぶ自動販売機の大小を質問すると、「左」と回答。画像には直接書かれていない左右の概念を持っています。

「一番右の人の浴衣の色は?」という質問に対しては、「紫色」と回答。画像を見る限り、紫色というよりは薄墨色といった感じで、色の見分けについては精度がそこまで高くない模様。

Stability AIは「このモデル(Japanese InstructBLIP Alpha)の活用例として、画像を用いた検索エンジン、目の前に情景説明や質疑応答、そして目の不自由な方などに画像について文字で説明する、などが考えられます」とコメントしています。
なお、Japanese StableLM AlphaはHugging Face Hubで、Hugging Face Transformersに準拠する形式で「JAPANESE STABLELM RESEARCH LICENSE AGREEMENT」に基づいて公開されています。
