
無料&ブラウザ上でPDF・JPEG・PNG・GIFファイルからOCRによるテキスト抽出ができる「OCR PDFs and images directly in your browser」


PNG・JPEG・GIFといった画像ファイルやPDFファイルから、TesseractによるOCR(光学文字認識)でテキストを抽出できる「OCR PDFs and images directly in your browser」をエンジニアのサイモン・ウィルソン氏が公開しました。OCR PDFs and images directly in your browserはすべての処理をブラウザ上で実行するため、ファイルをどこかのサーバーにアップロードすることがないというのが大きな特徴です。
https://tools.simonwillison.net/ocr
Running OCR against PDFs and images directly in your browser
https://simonwillison.net/2024/Mar/30/ocr-pdfs-images/
OCR PDFs and images directly in your browserにアクセスするとこんな感じ。

まずは画像ファイルの読み込みを試すべく、ルイス・キャロルの「不思議の国のアリス」の冒頭をスクリーンショットした画像(PNG形式)をOCR PDFs and images directly in your browserに読み込ませてみます。

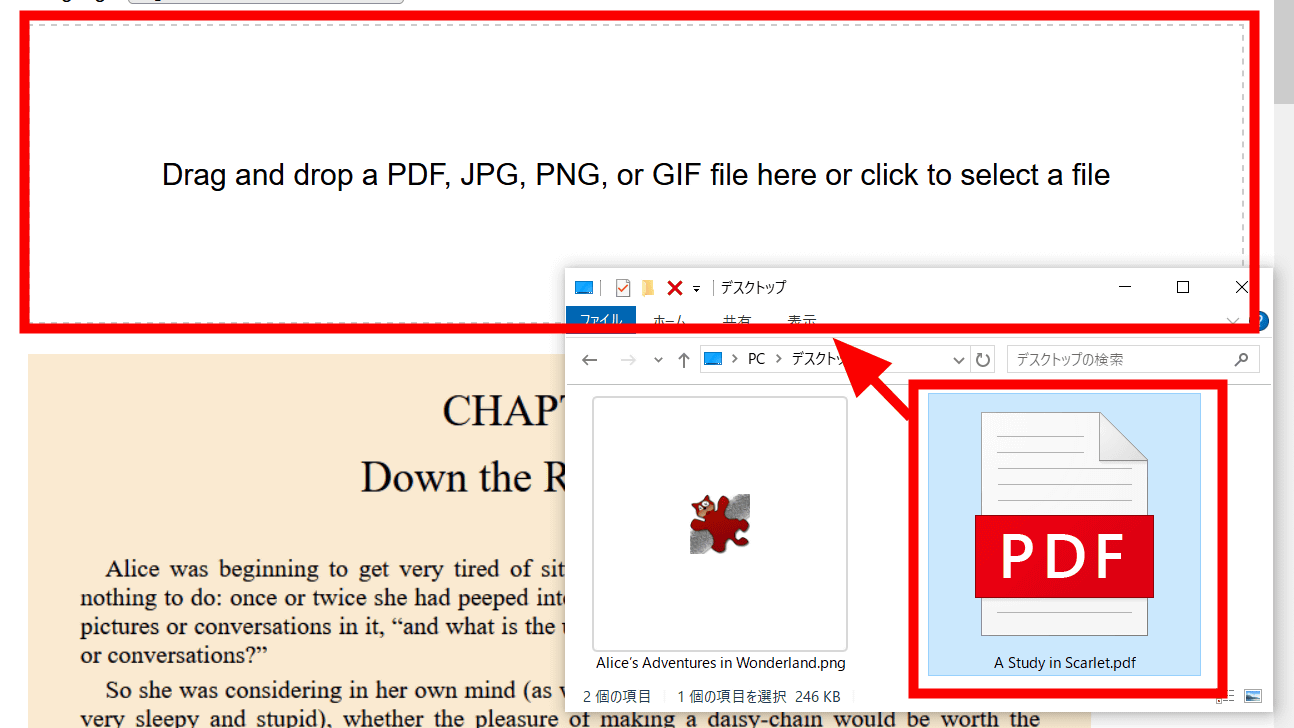
OCRにかけたい画像を、OCR PDFs and images directly in your browserの「Drag and drop a PDF, JPG, PNG, or GIF file here or click to select a file」と書かれた領域にドラッグ&ドロップします。

すると、画像ファイルが読み込まれ、十数秒で以下の赤枠部分に抽出されたテキストが表示されました。OCRの精度は高く、しっかりと抽出できています。

次に、PDFファイルを読み込んでみました。アーサー・コナン・ドイルの「緋色の研究」の冒頭部分をPDFファイル化したものをドラッグ&ドロップ。

以下のようにテキストが読み出されました。なお、ウィルソン氏によれば、複数の段組で構成されているPDFファイルだとテキスト抽出の精度が落ちてしまうそうです。

OCR PDFs and images directly in your browserは英語だけではなく、日本語を含むさまざまな言語に対応しています。抽出する言語を変更するには、「Language」の項目で「Japanese」を選択すればOK。

試しに、GIGAZINEの記事をスクリーンショットした以下の画像を読み込んでみました。

画像から記事のテキストが抽出されましたが、以下の画像を見るとわかる通り、文字の間隔がバラバラになったり存在しない漢字が挿入されたりと、英語よりかなり精度は落ちてしまう模様。それでもかなりのスピードでテキストを抽出することが可能です。

OCR PDFs and images directly in your browserはオープンソースで開発されており、ソースコードが以下のGitHubリポジトリで公開されています。
tools/ocr.html at main · simonw/tools · GitHub
https://github.com/simonw/tools/blob/main/ocr.html
ウィルソン氏はOCR PDFs and images directly in your browserを開発した動機について、「PDFファイルや画像からデータを取り出す方法として、近年ではGemini Pro 1.5やClaude 3、GPT-4などの大規模言語モデルで非常に有望な結果が得られています。しかし、これらのツールはほとんどの人にとって依然として不便です。一方、 Tesseract OCRのような古いツールは依然として非常に便利です」とコメントしています。なお、OCR PDFs and images directly in your browserの開発にはClaude 3やChatGPTが使われているそうです。





