
Metaがコード生成AIモデルの新バージョン「Code Llama 70B」をリリース、コードの正確性が向上・Pythonに最適化されたバリアントも提供


FacebookやInstagramを運営するMetaが、テキスト入力を元にプログラムのコードを生成するAI「Code Llama」の700億パラメータのモデルをリリースしたと発表しました。モデルはLlama 2と同じ「Llama 2 Community License」で公開されており、月間アクティブユーザー数が7億人以下の場合は無償で商用利用することが可能です。
Introducing Code Llama, a state-of-the-art large language model for coding

Code LlamaはMetaが2023年7月にリリースしたLlama 2をコード固有のデータセットでさらにトレーニングしたもの。Python、C++、Java、PHP、Typescript&Javascript、C#、Bashに対応しており、コードの続きを生成する機能のほか、自然言語での入力を元にコードを生成したり、コードについての解説を生成したりすることが可能で、2023年8月にパラメータ数が70億、130億、340億のモデルがリリースされていました。
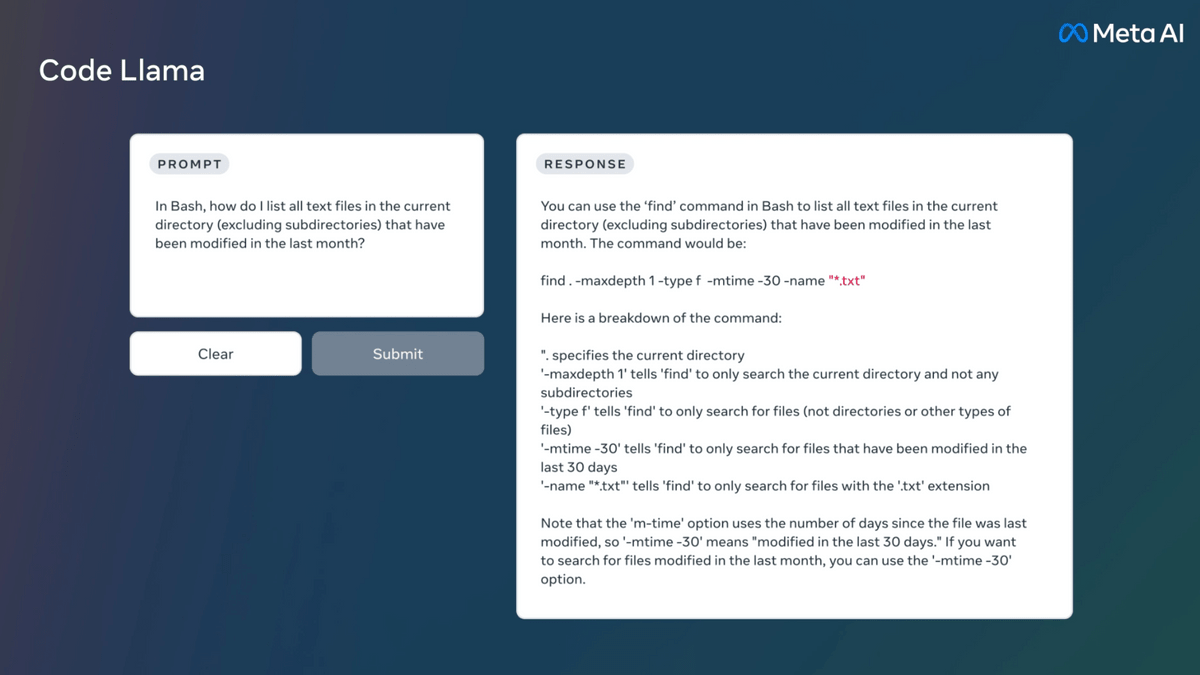
2024年1月29日、Metaは700億パラメータの「Llama 2 70B」モデルをベースにコード固有のデータセットで追加トレーニングを施した「Code Llama 70B」モデルをリリースしました。他のサイズのモデルのトレーニングデータが5000億トークンなのに対し、700億パラメータモデルでは1兆トークンでトレーニングを行ったとのこと。さらに、目的ごとにファインチューニングを施すことで基本となる「Code Llama」のほか、自然言語からのプログラミングというタスクに特化した「Code Llama - Instruct」やPythonの取り扱いに特化した「Code Llama - Python」というバリアントが用意されています。

「HumanEval」と「MBPP」を使用して計測した700億パラメータのモデルとその他のモデルの性能比較の結果は下図の通り。InstructモデルがGPT-4を超える性能を記録したほか、3つのバリアント全てにおいて順当に性能が向上していることが分かります。

Code LlamaのモデルについてはMetaに申請することで入手できるほか、Hugging Faceでもホスティングされています。




![アン・ソンジェ氏(左)と日本の元野球選手イチロー。[ユーチューブ キャプチャー]](https://image.news.livedoor.com/newsimage/stf/8/5/858d1_204_93f82bee_66a71335-cm.jpg?v=20240925123834)
