
たった1枚の画像から別視点の画像を生成するAIモデル「Zero-1-to-3」をトヨタ・リサーチ・インスティテュートなどの研究チームが開発


オブジェクトの画像を1枚入力するだけで、視点を変えた高精度の画像を生成できるAIモデル「Zero-1-to-3」を、アメリカのコロンビア大学やトヨタ自動車の研究機関であるトヨタ・リサーチ・インスティテュートの研究チームが開発しました。実際にZero-1-to-3がどれほどの性能を持っているのかを試せるデモページも公開されています。
[2303.11328] Zero-1-to-3: Zero-shot One Image to 3D Object

Zero-1-to-3: Zero-shot One Image to 3D Object
https://zero123.cs.columbia.edu/
Zero-1-to-3は大規模な拡散モデルを使用して相対的なカメラの視点制御を学習したAIモデルであり、たった1枚のRGB画像からカメラの視点を変えた画像を出力できます。
以下の画像は、画像生成AIのDALL・E 2で生成した画像をZero-1-to-3に入力し、さまざまな視点の画像を出力させてみた結果を示したもの。1つの視点からオブジェクトを見た入力画像から、異なる視点から見たオブジェクトをかなり正確に再現できていることがわかります。

また、Zero-1-to-3を使用して生成した「さまざまな視点から見たオブジェクトの画像」を組み合わせることで、完全な3Dモデルを再構成することも可能です。

Zero-1-to-3について解説する公式ページでは、テスト画像を使用して異なる角度の画像を出力させられるデモも公開されています。「options」の項目から入力画像を選択できるので、今回は「car1」を選択。

「Polar angle(垂直方向の角度)」「Azimuth angle(水平方向の角度)」「Zoom(ズーム)」「Random seed(ランダムシード値)」をスライドバーで設定し、「Generate Novel Vies(新しいビューを生成)」をクリック。

すると、設定した視点から見た画像が生成されました。

1つだけでなく、さまざまな視点からの画像を生成することができます。

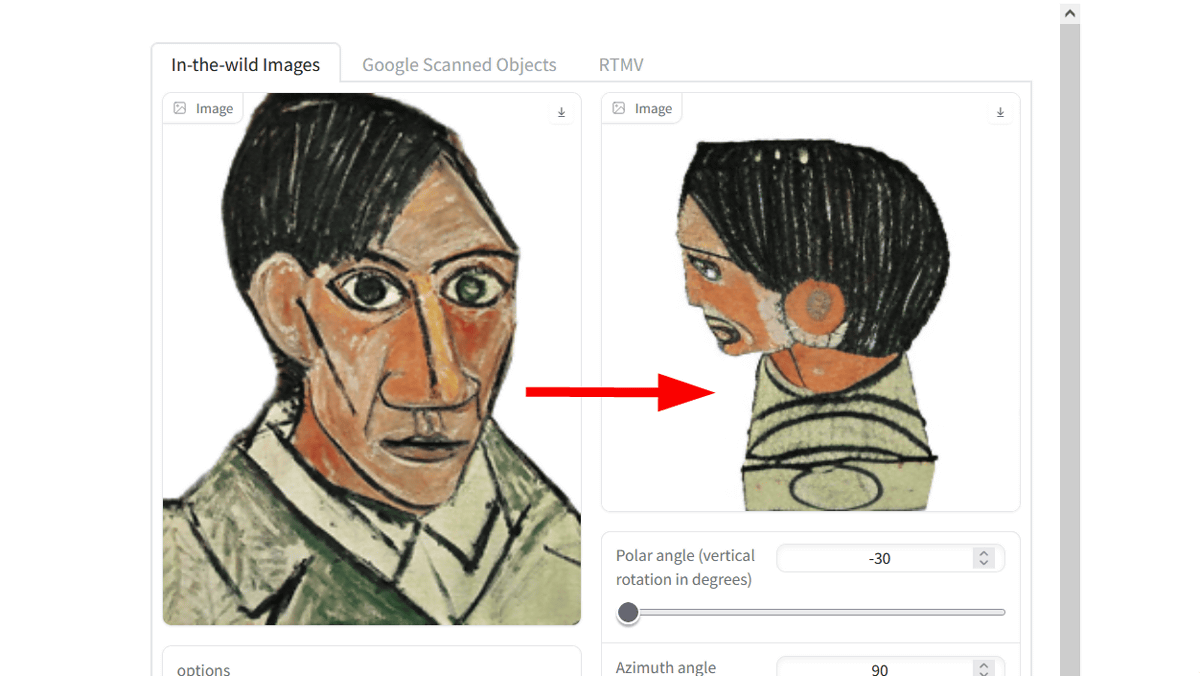
絵画タッチの画像でも動作します。

AI関連のリポジトリサイト・Hugging FaceにもZero-1-to-3のデモページが公開されており、自身の好きな画像を入力して視点の異なる画像を出力させることが可能です。
Zero-1-to-3 Live Demo - a Hugging Face Space by cvlab
https://huggingface.co/spaces/cvlab/zero123-live






