Googleが音声翻訳で話者の声を保ったまま翻訳させる画期的なシステム「Translatotron」を発表



by rawpixel.com
Googleが、人が話した内容を本人の声を保ったまま音声翻訳してくれる「Translatotron(トランスラトトロン)」について詳細を明かしました。従来モデルとは異なるエンドツーエンドモデルを採用した画期的なシステムとなっており、音声翻訳の未来を切り開くものと考えられています。
Google AI Blog: Introducing Translatotron: An End-to-End Speech-to-Speech Translation Model
これまでの音声翻訳では、まず話者が話した内容が自動音声認識により文章として起こされ、そこから機械翻訳を通して音声出力を行うという形が採られていました。音声-テキスト-音声という異なる翻訳方法を組み合わせた「カスケードモデル」が従来の方法だったのに対し、Translatotronは最初から最後まで音声翻訳で完結するというエンドツーエンドの手法が採られているのが特徴です。プロセスがシンプルであるがゆえに従来の方法よりも迅速な翻訳が行えるとのこと。
「私の知る限り、Translatotronは1つの言語から別の言語へ、音声を直接翻訳した初めてのモデルです。またTranslatotronは翻訳後の音声において、話者の声を保つことも可能です」とGoogleの研究者は述べています。

by Gratisography
機械翻訳の品質評価法であるBLEUスコアで示されるTranslatotronの精度はカスケードのシステムよりも少し低いのですが、カスケードモデルの翻訳の基準値以上の正確性は持っているそうです。
機械翻訳のエンドツーエンドモデルは2016年の論文で初めて発表され、それ以来、研究が続けられてきました。エンドツーエンドのモデルはカスケードモデルよりも優れているということが2017年には実証されています。
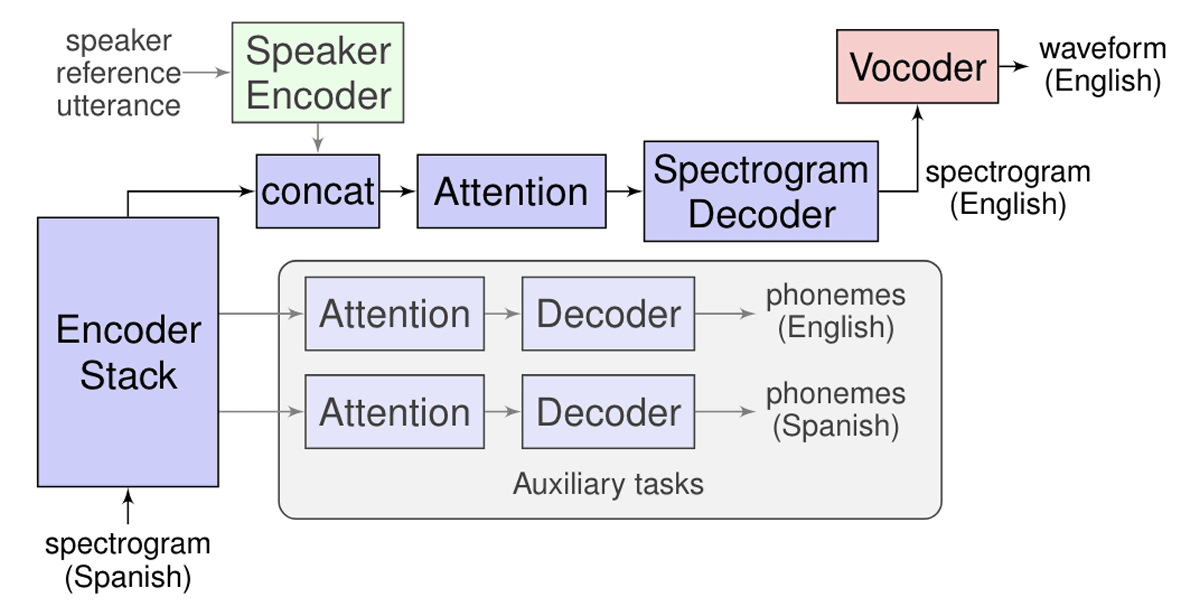
Translatotronはスペクトログラムの情報を入力として受け取り、ターゲットとする言語の翻訳コンテンツをスペクトログラムとして生み出すSequence to Sequenceのネットワークを基礎としています。また出力したスペクトログラムをタイムドメインの波形に変えるという「ニューラル・ヴォコーダー」を使用していることや、話者の音声を維持して翻訳後の音声を合成する「スピーカー・エンコーダー」を使用しているのも特徴です。

Translatotronによる実際の音声翻訳は以下のページから確認可能。「Input (Spanish)」が翻訳前の音声、「Translatotron translation (original speaker’s voice)」が声の調子を維持したまま翻訳が行われた音声です。
Google AI Blog: Introducing Translatotron: An End-to-End Speech-to-Speech Translation Model
このほか、ここからTranslatotronの音声翻訳を聞くことができます。
