
日本語・英語・中国語でたった3秒の音声から人の声を再現可能なMicrosoftの「VALL-E-X」を独自にトレーニングしたゼロショットモデルが公開中


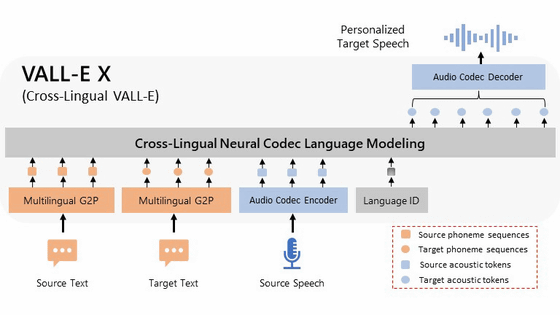
Microsoftが公開する「VALL-E」は、たった3秒間の音声サンプルから人の声を再現できる音声合成AIです。このVALL-Eで英語以外にも対応した「VALL-E X」を独自にトレーニングしたゼロショットモデルが、GitHubで公開されています。
GitHub - Plachtaa/VALL-E-X: An open source implementation of Microsoft's VALL-E X zero-shot TTS model. Demo is available in https://plachtaa.github.io
VALL-EがどういうAIなのかは以下の記事を読むとわかります。
Microsoftがたった3秒のサンプルから人の声を再現できる音声合成AI「VALL-E」を発表 - GIGAZINE

VALL-E XはVALL-Eを拡張したモデルで、ソース言語の音声とターゲット言語のテキストの両方をプロンプトとして使用します。例えば「英語で話す音声」と「中国語の文章」を入力することで、再現した音声に中国語を読み上げさせることが可能になります。
MicrosoftはVALL-E Xについて、(PDFファイル)研究論文やモデルの概要を発表していますが、ソースコードや事前トレーニング済みのモデルの公開はしていません。南洋理工大学電気電子工学部の学生であるSongting Liu(Plachta)氏のチームは、このVALL-E Xを再現する独自のモデルを一からトレーニングし、ソースコードとモデルを公開しています。
MicrosoftのVALL-E Xの対応言語は英語と中国語のみでしたが、Plachta氏のVALL-E Xは日本語にも対応しているのが大きな特徴です。Plachta氏のVALL-E-Xのデモは、以下のHugging Faceで体験できます。
VALL E X - a Hugging Face Space by Plachta
https://huggingface.co/spaces/Plachta/VALL-E-X
Hugging Faceのデモページにアクセスするとこんな感じ。

今回は英語でニュースを読む以下の音声ファイルを読み込ませ、日本語であいさつする音声を生成してみます。
「Text」に読み上げさせたい文章を、「language」にTextの言語を、「uploaded audio plompt」には元音声を読み込ませて、右上にある「Generate!」をクリック。

3分ほど待つと、右上に生成内容と生成された音声が表示されました。

実際に生成された音声がこんな感じ。元の音声がわずか数秒の短さということもあって、少しケロケロとしたひずみはあるものの、元の音声の声色に近いものが生成されています。
また、Plachta氏のVALL-E-Xによって生成された音声の例は、以下のデモページでも公開されています。
VALL-E
https://plachtaa.github.io/




