![[画像] Alder Lakeの内部構造を徹底検証、Zen 3&Rocket Lakeとも比較テスト - Alder Lake Deep Dive](https://image.news.livedoor.com/newsimage/stf/f/8/f8325_1223_865116c6cdcb0fc50f77f7b8036179b1-m.jpg)
●CineBench / POV-Ray / oneMKL Benchmarks
Alder Lakeこと第12世代Coreプロセッサの性能評価は11月頭にお届けしたが、この時は時間の関係&ベンチマークの関係でいくつか落としたテストがある。今回はこれを補う意味で、もう少しAlder Lakeの内部構造の確認を行ってみたいと思う。
ちなみに今回紹介するテストの環境は「原則として」前回紹介した構成そのままである。変更があったものだけ、その都度ご紹介したい。
○◆CineBench R23(グラフ1)
CineBench R23
Maxon
https://www.maxon.net/ja/cinebench
前回CineBenchのAlder LakeではP-Core/E-Core無関係に全コアを有効にして比較したが、今回はP-Coreのみの結果を加味した。ちなみにこの設定はProcessor Affinityの変更で行ったのだが、E-Core(Core i9-12900Kの場合ならCPU 16〜CPU 23)だけを割り当てるようにしたところCineBenchがまともに実行できなかった。そんなわけでE-Coreのみのデータは残念ながら取れていない。ちなみに今回利用したROG MAXIMUS Z690 HEROの場合、BIOS SetupでE-Coreを0にする(完全無効化)事は可能だが(Photo01)、P-Coreを0にすることは出来ない(Photo02)ため、この方法でE-Coreのみの性能を評価する事も不可能である。

ということで結果がグラフ1である。Multiの場合、E-Coreまで有効にすると27193、P-Coreのみだと19550ということで、差し引き7643がE-Coreの分という計算になる。ただこれはSingleの場合で比較しても判るが、Zen 3ベースのRyzen 9 5950XとはIPCそのものがだいぶ違う様で、結果8コアのCore i9-12900Kは16コアのRyzen 9 5950Xの23%落ちという猛烈に高い性能を発揮している事になる。もっとも前回のこれを見て頂くと判るが、消費電力そのものはこれもブッチギリでCore i9-12900Kの方が高い訳で、ここからE-Core 8コア分を抜いても、Ryzen 9 5950Xと同等になるとは思えない。「性能は高いが、消費電力もまた高い」あたり、性能/消費電力比で考えると微妙な感じではある。
○◆POV-Ray V3.8.2 Beta2(グラフ2)
POV-Ray V3.8.2 Beta2
Persistence of Vision Raytracer Pty. Ltd
http://www.povray.org/
同様にPOV-Rayも。こちらはCineBenchと違って、実際に処理速度(PPS:Pixels Per Second)の比較であるが、傾向としては似たようなものである。実際、One CPUにおける性能を比較した場合、Ryzen 9 5950XはAlder Lakeの3割落ちという辺りで、なのでP-CoreのみのAlder LakeのAll CPUの結果がRyzen 9 5950Xの9割弱というのは、まぁ妥当と言えば妥当な結果である。もっともこれに関しても、消費電力の枠を考えないからこういう議論になる訳で、仮にP-Coreのみで16コア集積したら、性能はRyzen 9 5950Xの2倍近くになるが、消費電力も軽く2倍を超えるだろう。
○◆Intel oneAPI Math Kernel Library Benchmarks Suite 2021.2.0_109(グラフ3)
Intel oneAPI Math Kernel Library Benchmarks Suite 2021.2.0_109
Intel
https://www.intel.com/content/www/us/en/developer/articles/technical/onemkl-benchmarks-suite.html
今回、P-CoreのみのCore i9-12900Kを追加してみた。その結果がなかなか面白い。Size/LDAが20000手前で言えば、Core i9-12900Kの方が性能の立ち上がりは早いが、その先で言えばほぼCore i9-11900Kと同等になっている。これはおそらくAVX2ユニットの性能がボトルネック(というか、もうこれ以上の性能が出ない)というところに来ているものと考えられる。後で細かく説明するが、Alder LakeのP-CoreことGolden Cove、フロントエンドやバックエンドに確かに手が入っているものの、FPU/SIMDに関して言えば実行ユニットなどは(Rocket Lakeに搭載されるCypress Coveと)同じであり、結果動作周波数が同じなら性能も同じ、という結果がはっきり見えたことになる。
ついでに言えば、P-CoreのみのCore i9-12900Kが最大で533.14GFlops。P-Core+E-Coreだと711.40GFlopsということは、E-Coreのみだと178.26GFlops。動作周波数の差(E-Coreは最大でも3.9GHzどまり)とかHyper-Threadingが無い(から、AVXユニットの利用効率がやや落ちる)事を加味しても、ラフに言ってCycleあたりのAVX2の処理命令数はP-Coreの1/3と考えていいだろう。
実際この数字は構成にあっている。P-Coreはこちらにもあるように、Port 00/01/05の3つでFMAを発行できるが、E-Coreにはこちらで示されている様に、そもそもFMAが無いので、Port 20/21を両方使ってFMULとFADDをそれぞれ実行する形になる。なので、1cycleあたりのFMAのピーク性能は1/3に落ちる計算で、数字上もこれが確認された格好だ。
●Sandra 20/21
○◆Sandra 20/21 2021.11.31.53 Tech Support(グラフ4〜56)
Sandra 20/21 2021.11.31.53 Tech Support
SiSoftware
https://www.sisoftware.co.uk/
前回のレポートでは、SandraがAlder LakeだとMemory Latencyなどを正しく測定できない(というか、Sandraそのものがクラッシュする)ということで数字が出せなかったのだが、最新版である2021.11.31.53ではこれが修正され、すべてのテストが問題なく動作する様になった。ただメモリ回りだけの修正なのかどうか不明なので、今回はCore i9-11900KとCore i9-12900K、それとRyzen 9 5950Xの3つについて全てデータを取り直したのでご紹介したい。ちなみにMT+MC(Multi-Thread+Multi-Core)はCore i9-12900KのP-Core/E-Coreの区別なく全コアで利用、MC(Multi-Core)ないし1T(One Thread)の場合はCore i9-12900KのP-Core(i9-12900K P)とE-Core(i9-12900K E)を分けて結果を示している。
ちなみに前回の2021.11.31.49→今回の2021.11.31.53では単にメモリ回りだけでなく結構あちこち手が入ったようで、結果がだいぶ変わっている。なので、前回のテストとは全く別物、と考えてほしい。

さてまずDhrystone(グラフ4・5)。MT+MC(グラフ4)では全般的に前より数字が落ちており、またRyzen 9 5950XがややCore i9-12900Kに劣っているあたりも興味深いが、それよりも面白いのが1T(グラフ5)。NativeだとP-CoreとE-Coreの間に大きな性能差があるのは当然だが、.NETだとP-CoreとE-Coreに差が見られなくなるのは、ハードウェア側の何かのボトルネックなのか、それともソフトウェア(.NETの実装)の問題なのか、興味あるところだ。

この傾向はWhetstone(グラフ6・7)も似ているが、こちらでは意外にRyzen 9 5950Xが健闘しているのが目に付く。このWhetstoneも面白く、特に1Tにおける.NET DoubleのE-CoreのスコアがNative Doubleより持ち上がっているのはどういう訳だろう? と疑問にならざるをえない。その意味ではちょっとベンチマークへの信頼性そのものが怪しい感じではあるのだが。



グラフ8〜11がProcessor Multimedia、つまりマンデルブロ図形の描画(≒複素演算のひたすら繰り返し)である。MT+MC(グラフ8・9)に関して言えばInteger/Float共にRyzen 9 5950Xが健闘しているという結果になるが、1T(グラフ10・11)でもRyzen 9 5950Xが悪くないスコアを出しているのはちょっと意外である。またNativeにおけるE-CoreのIntegerの性能はP-Coreのほぼ半分、Floatにおける性能は1/3強、というのは先に示したE-Coreの発行ポートの数を考えるともう少し頑張れても良い気がするのだが、あるいはNativeだと内部でFMA命令を発行しているのかもしれない。そもそもE-Coreの場合、Efficiency優先ということは、要するに「命令処理性能は高いがデータ処理性能はそこそこ」と完全に等価ではないにせよ、当然そうした傾向が無いとおかしいし、それを考えればまぁ十分と言えるのではないかと思う。



次のAES Encryption/Decryption(グラフ12・13)は、AES命令をサポートの性能評価と言えなくもないが、特にMT+MC(グラフ12)の場合はメモリ帯域も重要なファクターである。ここではDDR5を使えるCore i9-12900Kが圧勝しているわけだが、これはCore i9-11900KやRyzen 9 5950XはDDR4がボトルネックになっているという話であって、なので1T(グラフ13)だとほぼ同等であり、唯一E-Coreが大体半分程度のスループットになっているのは、恐らくE-Coreでは命令実行のスループットそのものが半分になっている(P-Coreでは1cycleで処理できるところが、2cycle掛かるとか)になっているものと想像される。「想像」というのは、まだAlder Lakeに対応したArchitecture Optimization Manualが公開されていないので確認できないためだ(これは後述)。
これに比べると専用命令の無いSHAではもう少し数字がばらついている。MT+MC(グラフ14)はまぁ理解できるが、今一つ理解できないのが1T(グラフ15)におけるCore i9-11900Kの異様に高いスコアである(もっともこれ、以前 https://news.mynavi.jp/article/20211104-2177568/images/209l.jpg も傾向として出ていたから、今回が初めてではない)。ただこれを除くと、E-CoreとP-Core、Ryzen 9 5950Xが大体横並びで、ただしSHA2-512のみE-Coreが異様に低く、逆にRyzen 9 5950Xが高いのは非常に納得できる。SHA2-512だとキャッシュラインで溢れる事が多く、結構メモリアクセス性能が効いてくる。E-Coreはおそらくこれがボトルネックになっており、逆にRyzen 9 5950Xは大容量L3でこれを補っている格好だ。

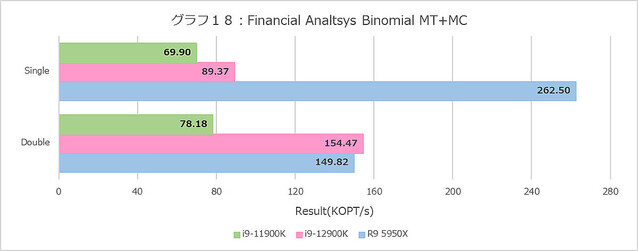



次はFinancial Analysis(グラフ16〜21)。まずBlack-Scholes(グラフ16・17)、MT+MCでSingle FloatだとRyzen 9 5950Xが最速なのにDouble FloatだとCore i9-12900Kがやや上回る、というのはなかなか興味深い。E-Coreの性能が低いのはまぁここまで見た通り当然であり、P-CoreがRyzen 9 5950Xを明確に上回るあたりは、Vector Unitの性能差というよりはデコード段の性能差なのかもしれない。
Binomial(グラフ18・19)は、ことSingle FloatだとRyzen 9 5950Xが飛びぬけており、ところがDouble Floatだと拮抗するという構図がMT+MCと1Tの両方で再現しているのは面白い。あとIntel系は、これはBlack-Scholesも同じだがDouble FloatがSingle Floatより高速というのも謎である。これに比べるとMonte Carlo(グラフ20・21)はまだ真っ当というべきか。傾向そのものはこれまでとよく似たもので、E-Coreはやはり性能がかなり落ちる事も同じである。





Scientific Analysis(グラフ22〜27)であるが、まずGEMM(グラフ22・23)で言うと、MT+MCはRyzen 9 5950Xが有利、1TではDGEMMではP-Coreが健闘するものの、SGEMMではRyzen 9 5950Xがちょっと優勢というあたり。E-Coreの性能はP-Coreのざっくり半分程度なので、Core i9-12900K全体でもRyzen 9 5950Xに敵わないのはまぁ順当である。
逆にFFT(グラフ24・25)で異様にCore i9-12900Kの性能が高いのは、主にメモリアクセスの帯域と考えられる。テストはSingle Floatで64MB、Double Floatで32MBのデータに対して行われる関係で、理論上はDouble FloatならばRyzen 9 5950XのL3にすっぽり入る筈だが、これを入れると他のものが全部入らなくなるわけで、実際にはそこまででFFTのデータを格納しきれておらず、足りない分は当然メモリアクセスになる。これはL3が30MBのCore i9-12900Kも事情は同じだが、そうなるとメモリの帯域差がそのまま結果に反映される格好になると思われる。1Tでもテストデータのサイズは変わらないが、MT+MCの時ほど激しくデータアクセスをするわけではないので、まだキャッシュが効きやすい結果がグラフ25、と考えれば良さそうだ。それにしても相変わらずCore i9-11900Kのスコアが高いのはどういう理由なのか?
N-Body(グラフ26・27)は、FFTに比べるとまだ順当というか、比較的理解しやすい結果になっている。ちなみにここでのE-CoreとP-Coreの性能比は4倍以上になっており、そういう意味でもE-Coreにはあまりデータ処理系の作業をさせてはいけない、という事が理解できる。





AI/ML(グラフ28〜33)は、Intel系の内蔵NPUであるGNAを使うようになっていないため、ちょっと非現実的なテストと言えなくもないのだが、まぁ演算性能の比較と割り切ればこれはこれでアリだろう。ちなみにGNAはIce Lake以降の全てのClient向けCPUに搭載されており、勿論Alder Lakeにも搭載されている。AMDはまだこの手のアクセラレータは特に搭載されていないが、これはこれで時間の問題という気もしなくはない。
さて、まずInference(グラフ28・29)だが、CNNとRNNで性能が結構変わることが面白い。CNNではCore i9-12900K最速だが、RNNではRyzen 9 5950Xが最速である。これはNormal/High Precisionの両方で共通であり、1Tの場合でもこの傾向がはっきり示されているのはちょっと珍しい。
一方Training(グラフ30・31)では、Ryzen 9 5950Xの性能の高さが際立つ格好になっている。Inferenceとは逆にRNNだとMT+MCではCore i9-12900Kにやや引けを取る結果になっているが、1Tではこちらも最速である。逆に言えば1Tで最速なのに、なんでMT+MCでは性能が芳しくないのか? という話だが、これはおそらくはメモリアクセス性能が効いてきているものと思われる。Trainingの場合、Inferenceよりもはるかにメモリうを必要とし、全Threadをフルに動かすとL3キャッシュ程度では収まらないと思われるためだ。そう考えると、特にRNNでCore i9-11900KとRyzen 9 5950Xのスコアが同程度なのが腑に落ちる(どちらもDDR4-3200)。
性能比較の最後はImage Processing(グラフ32・33)である。MT+MC(グラフ32)で言えば、勿論行う処理によって多少凸凹はあるが、概してCore i9-12900Kが高い性能を出している。ただ1T(グラフ33)を見ると、P-Coreの性能はすべてのケースでCore i9-11900K以下、というあたりはどういう理由なのか、もう少し分析をしたいところである。E-Coreは? というと、例えばNoise ReductionだとP-Coreの半分強なのに対し、DiffusionとかMotion Blurだと1/4程度という具合に性能のばらつきがかなり大きいのも特徴的である。E-CoreはSkylakeよりも効率が良いという話であったが、効率はともかくとして絶対性能という意味ではSkylakeにはちょっと遠いんじゃないか? と思わせる結果であった。





次はInter-Thread Efficiency(グラフ34〜39)である。まずグラフ34・35がLatencyの平均値である。Inter-Threadに関して言えばBest/Worst共にCore i9-12900KはCore i9-11900Kと同程度で、Ryzen 9 5950Xよりは3ns程度(ということは、10cycle前後?)遅い結果になっている。そしてこの段階ではE-CoreとP-Coreの間に差は見られない。面白いのはInter-Coreである。Core i9-12900KはP-Core同士がここに出てくるが、これも32.8〜33nsとCore i9-11900Kの30ns台よりやや余分に要しているし、Ryzen 9 5950Xの21.7〜21.8nsと比較しても結構遅い。そしてP-CoreとE-Coreの通信だと46ns前後、E-Core同士だと50〜51.8nsと更に遅くなることだ。E-Coreは4コアづつのクラスタになった形で配されるので、これを跨ぐ際にLatencyが余分にかかるのかもしれない。Inter-ModuleはRyzen 9 5950Xだけで、これはもう2つのダイの間の通信だから、一番Latencyが多いのは自明である。
ただそのLatencyについて頻度分布(グラフ36・37)を見ると、Core i9-12900Kでは特にInter-Core Latencyが結構バラつきが大きい事が見て取れる。勿論バラつきの幅の絶対値で言えばRyzen 9 5950XのInter-Moduleの方が大きいのだが、こちらはOff-Chipで、しかも2 Pass(CCD #1→IOD→CCD #2)になることを考えれば納得できるが、逆に物理的には1ダイの中に納まっているにも関わらず、特にP-Core/E-CoreとかE-Core同士で結構遅いあたりはちょっと理由が不明である。あるいはE-CoreではL2が4コア単位で共有になっているあたりが理由だろうか?
グラフ38・39はInter-Thread Bandwidthである。Inter-ThreadのBestとWorstで、実はLatencyはそれほど差が無いのだが、このBandwidthは大きく影響を受ける。実際結果を見るとその傾向が良く判る。
それはともかくとしてグラフ38を見ると、Intel系は16KBあたりがPeak Bandwidth、Ryzen 9 5950Xは256KBあたりがPeak Bandwidthになっているのは従来から同じであるが、改めてそのピークを見るとCore i9-12900KよりCore i9-11900Kの方が僅かながら上回っているあたりは、むしろこれE-Coreが足を引っ張っている可能性がありそうだ。
グラフ39だとRyzen 9 5950Xは全てInter-Moduleでの帯域となるので、常時15GB/sec弱という帯域に落ち込むのはまぁ致し方ないところ。それはともかく、ここではグラフ32と逆にCore i9-12900Kの方がやや帯域を稼げているが、これはコアの数そのものが増えているから、その分が上乗せになっている(要するにE-Coreの分)という事だと考えれば良いかと思う。

さて、ここからは前回のSandraではテストできなかったメモリ回りである。まず最初はMemory Bandwidth(グラフ40・41)。こちらではMT+MCは無くなっており、MC及び1Tの結果になっている。まずMC(グラフ40)で見ると、やはりStreamや256MB〜4GBのMemory Bandwidth AverageでCore i9-12900Kは40GB/secを叩き出し、30GB/sec台のCore i9-11900KやRyzen 9 5950Xを大きく引き離している。もっともよく見ると、P-Coreは確かに飛びぬけて性能が高いが、E-Coreはそれほどでもないというか、Core i9-11900KやRyzen 9 5950Xと同程度である。
考えられる要因2つあって、一つはLoad/Storeユニットの性能の差である。E-CoreはLoad Unit×3、Store Unit×2だが、AVX512を扱う必要が無いから恐らくデータ幅は256bitである。他方P-CoreはLoad Unit×2、Store Unit×2で一見数は少ないように見えるが、AVX512を扱う必要があるから、これもおそらくデータ幅は512bitである。なので、頑張っても768bit/cycleのE-Coreと1024bit/cycleのE-coreでは絶対性能が違うため、E-Coreを使ってもDDR5の帯域を利用しきれない、という話。
もう一つの可能性は、Ring Busに対してのボトルネックである。E-Coreの場合4コアまとめて一つのクラスタになっており、共有L2キャッシュを経由する。なので、E-Coreが8コアフルに動いても、実際には2つの共有L2キャッシュからRing Busへの帯域がメモリリクエストの上限になる。対してP-Coreは、それぞれのコアがRing Busに直接接する形になる。要するにRing BusへのI/F(Ring Stop)の数がボトルネックになるという可能性だ。現時点ではどちらがボトルネックか判らない(両方の可能性もある)が、1T(グラフ41)の場合でもE-Coreの性能はP-Coreの3/4程度、というあたりは前者の影響は間違いなくありそうである。

加えて言えば、E-Coreはキャッシュの帯域そのものも低く抑えられているようだ。グラフ42・43がCache & Memory Bandwidthであるが、ちょっと先に1T(グラフ43)を見ると、L1 D-Cacheの帯域は概ね160GB/sec弱。先に書いたようにAVX512は必要ないのでAVX2向けに32Bytes/cycleの帯域がL1 D-Cacheに用意されていると考えるべきで、仮にE-Coreの最大動作周波数である3.9GHzで動いているとすると理論上は125GB/sec程度になるが、これが160GB/secということは、ピークでは5GHz駆動ということになるが、これはCore i9-12900Kの仕様と合致しない。E-CoreのMax Turboは3.9GHzなので、ということはL1 D-Cacheの帯域は40Bytes/cycleということになるが、これもちょっと信じがたい。実際には32Bytes/cycleで3.9GHz駆動なのにも関わらず、何かベンチマークがおかしくて最大で160GB/sec出る事になってしまった、という方がまだ信じやすいのだが、このあたりを検証する方法が無いのでここでは措いておく。ついでに言えば、L2は概ね68〜70GB/sec程度。ということは、L1とL2は16Bytes前後で接続されている模様だ。
さて、これがMCになるとどうなるか、が非常に面白い。グラフ42でL1領域だと最大でも428GB/sec。8コアで、かつ3.9GHz動作だと13.7Bytes/cycle程度。まぁ多少動作周波数は下がって3.3GHz程度だとすれば、16Bytes/cycleということになる。なんで半減してしまったのか? という話だが、複数コアが動く場合はフルにL2が律速段階になってしまっているようだ。どうしてそういう仕組みになっているのか、はいくつか検討したが満足のいく仮説は立てられなかった。そろそろIntelにはAlder Lakeに対応したOptimization Reference Manualをリリースしてほしいところだ(現状は2021年6月付のみで、Ice Lakeまでの対応となっている)。
ちなみにP-Coreの方はほぼCore i9-11900Kと同じで、強いて言えばL2が512KB→1.25MBに大幅に増量されたことで、ピークがややずれた(512KB→1MB)ほか、L3も30MBに増量した事で、16MB/64MBにおけるBandwidthも多少上乗せになった程度である。











グラフ44〜55がLatencyである。Global DataとInst/Code、つまりデータキャッシュと命令キャッシュに対して、Sequential/In-Page Random/Full Randomの3種類のパターンでのアクセスを行った結果である。で、グラフが2つづつあるのは、L3 Hitまでの領域はLatencyをcycle数で判断するのが正確で、L3 MissはMemory Accessとなるのでこちらは実時間(ns)で比較するのが正確だからだ。グラフはcycle数、実時間の順で並べてあるので、最初のグラフはL3まで、その先は次のグラフで判断していただきたい。
まずはGlobal Data(グラフ44〜49)。Sequential(グラフ44)を見ると、L1でE-Coreが3cycleまで下げているのは中々面白い。一方P-Coreは5cycleでCore i9-11900K並み。Ryzen 9 5950Xは4cycleで、丁度中間である。L2になると、P-Coreは容量が増えたにも関わらずLatencyを3〜4cycle減らしており、一方E-Coreは共有L2という事もあってかちょっとP-Coreより多めだが、それでも9cycle程度でかなり優秀である。L3は更にLatencyが増え11cycleだが、それでもCore i9-11900Kより1cycle減らしている訳で、全般的にL2/L3キャッシュ周りの低Latency化に注力した感じだ。謎なのは8MBから先。本来P-CoreもE-Coreも同じメモリコントローラ経由でのアクセスだし、実際1Gあたりになるとどちらも5.2nsなのだが、その手前で妙にP-CoreのLatencyが増えているのは不思議である。ただCore i9-11900Kの4.3nsに比べると1nsほどLatencyが増えるのはDDR5に起因するのか、Memory Controllerの作りの問題なのかはこれだけでは断言できない。またSequentialに関して言えば、Ryzen 9 5950Xの優秀さが光る格好で、メモリアクセスも一番Latencyが少ない。
In-Page Random(グラフ46・47)になると、L1は変わらないがL2ではE-Coreが急激にLatencyを増やしているのは、やはり共有L2という構成に起因するものだろうか? ただL3に関しては、むしろE-CoreよりややLatencyがすくないのは不思議なところ。このIn-Page RandomではRyzen 9 5950XのLatencyがL3〜Memoryで急に大きくなっている様にも見えるが、実際はIntel系が低く抑えている、というべきか。あとMemory領域ではE-CoreとP-CoreのLatencyが明確に違うのは、Load/Storeユニットの動作に起因するというよりも、P-Coreの共有L2の動作に起因するのかもしれない。
Full Random(グラフ48・49)では逆にRyzen 9 5950XのLatencyはそれほど極端に大きくはなく、逆にE-CoreのLatencyの大きさが目立つ格好になる。特に1GBだと、Latencyそのものは500cycle前後に見えるが、実際にはE-Coreのみ120ns台のLatencyになっているのはちょっと不思議である。
一方Inst/Code Cache(グラフ50〜55)。Sequential(グラフ50・51)でL1はさすがにどのコアも1cycleでこれは不思議ではない。ただL2に入ると結構バラつきが出てくる。意外に暴れるのがRyzen 9 5950Xであり、逆にP-CoreはL2までは非常に優秀である。ここでもE-Coreは結構大き目の印象であり、特にMemory Accessになると11ns台までLatencyが増えるのはちょっと不思議である。
In-Page Random(グラフ50・51)になると差が減る印象である。強いて言えば、L3 Missから急速にP-CoreのLatencyが増えるのがちょっと不思議であり、逆にE-Coreは低め安定という感じだが、Memory Accessになるとどちらも22ns台で、16ns弱のCore i9-11900Kよりちょっと大きいのは、やはりMemory Controllerの違い(なのかDDR4/5の違いなのかは定かではないが)に起因するのであろう。
Full Random(グラフ54・55)ではL2におけるP-CoreのLatencyの低さがちょっと目立つ。これはL3も同じで、Ryzen 9 5950XはもとよりCore i9-11900Kと比較しても少ないのは優秀と言える。ただMemory Accessに関して言えば、Core i9-11900KよりややLatencyが増えているのは、もうそういうものだという感じである。
最後にVideo Memory Bandwidth(グラフ56)を。要するにPCIeの速度であるが、これはもう見ての通りで大きな差はない。Core i9-12900KはPCIe Gen5対応になってはいるが、その本領が発揮されるのはPCIe Gen5対応の拡張カードを利用した場合のみであり、PCIe Gen4対応のGeForce RTX 3080では差が無くて当然である。逆に言えば、PCIe Gen4カードを装着するとPCIe Gen4と変わらない振る舞いをする、という事が確認できた格好だ。
●RMMA 3.8
○◆RMMA 3.8(グラフ57〜142)
RMMA 3.8
Rightmark.org
http://cpu.rightmark.org/products/rmma.shtml
さて久々のRightMarkである。今回これに関してのみ、OSはWindows 10に戻して実施している。結果としてAlder LakeのThread Directorは動作しない事になるが、RMMAの性格上これはむしろ好都合でもある。
そのRMMAだが、今回Alder LakeはP-Coreのみのテストである。一応RMMAそのものは立ち上がる(Photo03)のだが、Task ManagerのProcessor Affinityを使ってE-Coreのみを割り当てると、テストが正常に稼働しない(Photo04)。Photo02でも示したようにP-Coreを全て無効にする方策が無いので、今回はP-Coreのみの比較である。

また、Ryzen 5000シリーズのレビューに、「後ほどDeep DiveでRMMAの結果をお届けする」とか言いつつ記事化が遅れており、加えてRocket LakeのレビューでもRMMAのデータを取得しつつ、記事にはしていなかった。そのあたりも含め、今回は5世代のCPUコアのデータを比較してみたいと思う。対象としたのは
Comet Lake : Core i9-10900K
Rocket Lake: Core i9-11900K
Alder Lake : Core i9-12900K
Zen 2 : Ryzen 7 3800X
Zen 3 : Ryzen 9 5950X
の5つである。いずれもWindows 10の環境での測定で、またBIOS Setupで動作周波数を固定しての測定である。
ということで、まずはDecode Bandwidth(グラフ57〜71)。以前もどこかに書いた気がするのだが、Decode Bandwidthでは
NOP(1):nop
SUB(2):sub eax, eax
XOR(2):xor eax, eax
TEST(2):test eax, eax
XOR/ADD(4):xor eax, eax; add eax, eax
CMP #1(2):cmp eax, eax
CMP #2(4):cmp ax, 0x00
CMP #3(6):cmp eax, 0x00000000
CMP #4(6):cmp eax, 0x0000007f
CMP #5(6):cmp eax, 0x00007fff
CMP #6(6):cmp eax, 0x7fffffff
Prefixed CMP #1(8): cmp eax, 0x00000000
Prefixed CMP #2(8): cmp eax, 0x0000007f
Prefixed CMP #3(8): cmp eax, 0x00007fff
Prefixed CMP #4(8): cmp eax, 0x7fffffff
という15種類の命令をDecodeする際に、どの程度のThroughputでこれを処理できるかから、Decode段の性能を比較するものだ。ちなみに上のリストで()内は命令のByte数である。ということで早速見てみたい。
まずNOP(グラフ57)。Zen 3は最初3KB付近までは6Bytes/cycleを実現しているが、これはμOp Cacheによるもので、その先は4Bytes/cycleに落ちている。とはいえZen 2だとこれが5Bytes/cycleだから、μOp Cacheの帯域が最大6命令/cycleに増強されたのが良く判る。そしてComet LakeとRocket Lakeは意外にもどちらも4Bytes/cycleで安定している。これはμOp Cacheが無いわけではなく、どうもNOPに関してはμOp Cacheの対象にしていない様な振る舞いに見える。これはAlder Lakeも同じなのだが、こちらは5.7Bytes/cycle程度でStableなあたりは、純粋にDecode性能の向上が効いている感じだ。実際Alder Lakeは6命令/cycleのDecoderを搭載しているという話だから、これは辻褄が会う。実際100KBあたりの数値で見れば、Alder Lakeのみが6命令/cycleに近く、他は全て4命令/cycleで動作している。

ただしAlder LakeのDecoder、相変わらずIntelの伝統のAsymmetricな構成らしい。次のSUB(グラフ58)。命令長が2BytesだからBandwidthの数字は2倍になるのはいいとして、Alder Lakeを見るとμOp Cacheが効く範囲は6命令/cycleだが、その先では5命令/Cycleに落ちている。ただ、同じ2Bytes命令のXOR(グラフ59)を見ると、Cacheが効く範囲では6命令/Cycle近くを維持しているあたりは、Decodeそのものは6命令/cycleが可能で、ただし6命令/cycleで動ける命令には制限がある、というあたりだろうか。
余談ながら、グラフ58を見るとAlder LakeのμOp Cacheが4K命令分という先の図の説明が正しい事が判るし、Zen 3もやはり4K命令分を搭載しているようだ。Rocket Lakeは5命令/cycleのμOp Cacheであり、3KBあたりから効果が薄れているあたりは1.5K命令相当になるが、発表では2.25K命令分とされているので、これは圧縮して格納されているのだろう。ちなみにZen 2ではL1 Miss/L2 HitあたりからちょくちょくBandwidthが落ちる傾向があるが、Zen 3ではこれが改善され、L3 Missまでの間ほぼフラットに4命令/cycleを実現できている事も判る。
また一部の命令はμOp Cacheも効果ないようだ。それがTEST(グラフ60)で、ここではAlder Lakeも5命令/cycle、その他のコアは全て4命令/cycleになっている。これはもうμOp Cacheを使わずに、それぞれのDecoderが動作している格好だ。



次も面白い。XOR/ADD(グラフ61)では、なぜかAlder LakeではうまくμOp Cacheが動作しないようで、5.3命令/cycleという良く判らないスループットになっている。次のCMP $1(グラフ62)ではμOp Cacheが動作していないようで、5命令/cycleでフラットという事になっている。この辺の処理は、Decodeそのものは4命令/cycleながら、ちゃんと6命令/CycleでμOp Cacheから供給されるZen 3の方が優秀に見える。もっともCMP #2(グラフ63)だとそのZen 3もμOp Cacheが無効化されてしまっているし、CMP #3(グラフ64)だとAlder Lake以外はL1容量がボトルネックになって16KBあたりから落ち込んでいるのに対し、Alder Lakeは32KBあたりまで踏ん張るのは見事である。






この傾向はCMP #4〜#6(グラフ65〜67)でも同じである。さすがにPrefixed CMP(グラフ68〜71)になるとAlder Lakeもだいぶ鈍った波形になっており、L1の供給が間に合わなくなりつつなることが見て取れるが、そもそも8Byteの命令を大量に処理するというのは例外に近い事を考えると、かなりDecode段は強化されたとして良いかと思う。
ここまでで簡単にまとめると、
Alder Lakeはピーク6命令/CycleのDecoderを装備するが、実質的には5命令/Cycleに近い様に思われる。ただμOp Cacheは確かに6命令以上を供給できているのが判る。先のスライドにある様に、8 μOp/cycleで供給できているかどうか、は今回は確認できない(何となくAllocate段がボトルネックになっている感じがする:Macro Op Fusionを掛けるようなケースでしか8μOp/Cycleは達成できない感じだ)。
Zen 3はDecodeこそ4命令/cycleながら、μOp Cacheは増量され、この範囲ではAlder Lakeに肩を並べる性能を持つ。同じ4命令/CycleのComet LakeやRocket Lakeよりもこの部分は優れた実装になっており、Zen 2と比較しても改善が明白である
というあたりだろうか。ただしこれはDecode段だけの話であるが。
Decodeでもう一つ、Decode Efficiencyをグラフ72に示す。要するにNOP命令の前に無駄にPrefixをどんどんつけてゆくとどうなるか、という話である。Prefixを付けると通常のDecoderでは処理できずにMicrocodeによる解釈になるので、Prefixを付けないと4〜6命令/cycleで処理されていたものがいきなりMicrocode扱いになり、Throughputが落ちるのはまぁ当然である。ただそこから先のThroughputで言えば、IntelよりAMDの方が効率よく処理が出来る。NOP Countが14(命令長15Bytes)で言えば、Intelが1命令の処理に136〜167cycleを要するのに対し、Zen 2/3は65cycle程度で処理が出来ている。まぁMicrocodeを使う様なケースがどの程度あるか? と言われれは現状ではかなりレアだと言わざるを得ないので、これで性能がどうこうという話にはならないが、Microcodeで言えばZen 2/3の完成度の方が高い(というか、Intel側が手を抜いている?)感じだ。それにしてもAlder Lakeが一番スループットが低いのはどうしたものか。



Decode段の確認のついでにI-ROBのLatency(Photo73〜76)も。さすがに実行ユニットを大幅に増やしたこともあり、当然ここも強化しないといけなかったようで、Alder LakeはComet LakeやRocket Lakeよりも大幅に改善されている。ただZen 3がこれよりも更に良い成績を示しているのはなかなか興味深い。Zen 2と比べてもかなり改善されており、特にRandom(グラフ76)ではAlder Lakeを突き放すくらいに安定している。Zenアーキテクチャも3世代目に入り、内部構造がかなり成熟してきたことを感じさせる結果である。


さてパイプライン周りはこの辺にして、次はD-CacheのBandwidth(グラフ77〜79)。Bandwidthの絶対値が小さいのは、そもそもRMMAがAVXに未対応(なにせ2008年でリリースが止まっている)だからで、なので利用しているのはSSE2命令である。ということはアクセスの単位が128bit=16Bytesになるからで、Read(グラフ77)ではAlder Lakeがピークで3 Load/cycle、その他のコアは2 Load/cycleを実施できていると見るのが正しい。ピーク性能そのもので言えば、Alder LakeというかGolden Coveコアは潜在的に512bit×3=192Bytes/cycleの帯域をL1で持っていても不思議ではないのだが、現実問題としてAlder LakeではAVX512が無効化されているから、AVX2向けに256bit×3=96Bytes/cycle、他のコアは256bit×2=64Bytes/cycleがL1領域では可能になっているものと思われる。ちょっと先ほどのSandraのグラフ43(Cache & Memory Bandwidth 1T)に戻ると、Core i9-12900K P-CoreではSize 32KBの際に505.31GB/secの帯域になっている。1TだからTurbo Maxで動いていても不思議ではなく、仮に5.2GHz動作だと仮定して計算するとBandwidthは97.2Bytes/cycleといったところで、96Bytes/cycleという理論値に大体近い事になる。
一方でL2に入ると、例えば256KBの場合だと134.91GB/secで、同じく5.2GHz動作なら25.9Bytes/cycle程度。実際にグラフ77を見ると29Bytes/cycle程度で、Sandraの結果と大きく違わない辺りは、これはL2→L1の帯域がボトルネックになっていると考えられる。とはいえこの帯域はかなり優秀であって、Zen 2に次ぐものである。またL3も17Bytes/cycle程度の帯域を確保しており、これも(Zen 2/3にはやや見劣りしているが)Comet Lake/Rocket Lakeからの大幅な改善がみられる。逆にZen 2→Zen 3では、L2領域でややThroughputが落ちているのが気になるところだが、それ以外はほぼ同じである。
Write(グラフ78)は、そもそもStore Unitが2つだからAlder Lakeのピークそのものは32Bytes/cycleで共通だが、L2の帯域が20Bytes/cycle→22Bytes/cycle程度に向上している。この辺はComet Lakeから比べると随分性能が上がった格好だ。Zen 2/3は殆ど変わりがない。結果、Copy(グラフ79)では圧倒的にAlder Lakeが高速である、少なくともL1領域ではもう数の暴力というか、ReadとWriteのThroughputを上げれば当然こうなるよね、という結果そのものである。ただそれが通用するのはL2までで、L3領域以降は今一つといったところ。逆にL2以降ではZen 2/3が非常に良好で、特にZen 3はL3一杯の範囲で14Bytes/cycle程度を維持できているのは優秀である。ピーク馬力に振ったAlder Lake vs トルクに振ったZen 3とでも評すべきか。



次にLatency(グラフ80〜83)だが、Zen 2のみなぜか16MB〜32MBの範囲での測定にエラーが出るため、16MBまでの範囲の結果を示している。まずRead Forward(グラフ80)だが、これを見るとComet Lake→Rocket Lakeで大分L2→L3のLatencyが改善され、更にAlder Lakeでより一層改善されたことが判る。一方Zen 2→Zen 3では容量増加に伴うLatency増加を最小限に抑えており、こちらも優秀である。Backward(グラフ81)では、Comet LakeだけはLatencyの絶対値が増えているが、他のコアはForwardと変わらないLatencyを維持しているのも流石である。Pseudo-Random(グラフ82)では、Latencyの絶対値は大きく増えているのはまぁ当然として、傾向そのものは大きく変わらない。強いて言えば、L2/L3におけるAlder LakeのLatencyが妙に大きくなっている事だろうか? これはRandom(グラフ83)でも同じだが、L2/L3の大容量化によってトータルではComet Lake/Rocket Lakeより低めに抑えているあたりはよく出来ていると思う。





ついでにD-CacheのAssociativity(グラフ84〜89)についても確認しておく。先にリンクを示したOptimization Reference Manual及びAMDの資料によれば、L1〜L3のAssociativityは
ということになっている。まぁ一応これを検証してみようというものだ。ただRMMAの世代はまだL3が無かった時代なので、確認できるのはL1(グラフ84〜86)とL2(87〜89)のみである。
さてまずL1の方だが、Forward/Backward/Randomともほぼ同じ傾向になっているのは良いとして、Comet Lake/Rocket Lakeは5、Alder Lakeは7 SegmentからややLatencyが増えているのがちょっと気になるところだ。ただ8 segmentまではそれでも12cycle前後を維持しており、その先で急増しているあたりは一応8wayであるのは間違いなさそうである。ちなみにRocke Lake/Alder Lakeはなぜか13segmentまで維持されているあたりは、最初の4〜6 SegmentはL0相当の低Latency動作で、そこから8wayという動作なのだろうか? やや動きが疑問である。Zen 2/3はお手本通りの動作であるが、Zen 2が24segmentから激しく悪化するのに対し、Zen 3は64segmentあたりまでほぼ一定の、しかも低いLatencyを維持しているのは、このあたりをかなり改善したように見受けられる。
この傾向はL2でも同じだが、Latencyの絶対値そのものはL2そのものが遅い事もあってやや大きめである。それはともかくとして、L1ではRocket LakeとAlder Lakeはどちらも12segmentから急にLatencyが増えるのに対し、L2だとRocket Lakeが8segment、Alder Lakeは10segmentからLatencyが増えるといった形で、少し振る舞いが異なっているのは興味深い。L2のサイズそのもので言えばAlder Lakeの方が大きい事もあり、実際に16segmentあたりになるとAlder Lakeの方がLatencyの絶対値が大きくなるのはまぁ妥当だとは思うが、この傾向の変化は何かしらの改良が施された様に思う。一方Zen 2 vs Zen 3は、こちらもL1同様にZen 3が大幅に性能を改善していることが判る。







ついでI-Cacheについて。まずLatencyだが、こちらはNear Jump(グラフ90〜93)とFar Jump(94〜97)と数が多くなっている。まずNear Jumpであるが、Forward(グラフ90)におけるAlder LakeのLatencyの低さ(特にL0〜L2)は優秀として良いかと思う。L3では結構悪化しているが、これも30MBまで容量が増えた代償と考えれば妥当だろう。ただもっと改善しているのはZen 3で、Zen 2のLatencyの多さからは想像も出来ないほどLatencyが下がっている。
もっとも同じNear JumpのBackward(グラフ91)を比較すると、Zen 2はForwardと殆ど変わらないLatencyが維持されているのにそれ以外のコア特にL2〜L3領域で急速にLatencyを増やしているあたりは、より最適化が進んだと(つまり逆順アクセスを考慮しないで正順アクセスに全振りした)いうべきなのか。ただPseudo-Random(グラフ93)やRandom(グラフ94)ではZen 2はかなりLatencyが多い方に属しており、Alder Lakeが一番優秀という結果を見ると、Zen 3やAlder Lakeの方向性が正しいようにも思える。Pseudo-Random/Random(グラフ95・96)も、勿論Latencyの絶対値は上がるが傾向は似た感じだ。Alder LakeはRocket Lakeと比べると改善がはっきりわかるし、Zen 3もZen 2からの改善が著しい。
こうした傾向は、Far Jump(グラフ94〜97)も同じであり、若干Latencyが増えているかな、という程度である。Latencyの絶対値そのものはやや増えているが、傾向としてNear/Farで変化がない事は確認できた。


キャッシュの次はTLB周りについて。まずはD-TLBのSize比較(グラフ98〜100)である。先ほど同様にIntelとAMDの資料からTLBの構成を引っ張り出すと
となっている(いずれも4KB Pageの場合)。ちなみにZen 3ではL2がSharedではなく、L2 I-TLBが512、L2 D-TLBが2048という構成である。
さて、ではRMMAの結果を見てみたい。まずはForward(グラフ98)だが、どうもAlder LakeのL1 D-TLBは96 Entry構成になっているようだ。L2はRocket Lakeと同じく2048Entryだろうか? この傾向はBackward/Random(グラフ99・100)でも同じで、恐らくはL1 D-TLBのみを増強したように思える。またZen 2→Zen 3では、L2を非共用構成にしたためだろうか?500Entry以降のZen 3のLatencyの低さが目立つ。もっともRandomだと結構悪化しているあたりは、まだ改良の余地が若干ありそうではあるが。











次にD-TLBのAssociativity(グラフ101〜112)。要するに16/32/64/128-Way AssociativityでForward/Backward/Randomのアクセスを試した格好である。まず16way(グラフ101〜103)で見ると、L1の最小値そのものはComet Lakeが4cycleなのがRocket Lake/Alder Lakeでは5cycleに増えているのは、容量増加のためだろうか? また4/6segment以降にLatencyが増えるのは、早めにL2 TLBを見に行くためかもしれない。一応ここからもAlder LakeのL1 D-TLBはComet Lake/Rocket Lakeの1.5倍の容量がある様に見える。一方で見事なまでにフラットなのがZen 2/3である。
この傾向は32-way(グラフ104〜106)でも変わらないが、64-way(グラフ107〜109)になるとZen 3だけ破綻しているのがちょっと興味深い。またComet Lake/Rocket Lakeは3segmentあたりで妙なピークが出ているも不思議だ。
128-way(グラフ109〜112)ではZen 2/3がだいぶ破綻しており、大してIntel系はほぼコンスタント、というのは興味深いところ。それでもZen 3はZen 2に比べて10cycle以上Latencyを下げているあたりは、大容量L2 TLBを独自に持った効用だろうか?まぁ実際ここまでSegment分けが必要になるデータパターンというのはちょっと考えにくいものはあるのだが。それはさておき、ここから見るにAlder LakeのD-TLBはL1-Dが96Entry/6-way、L2が2048Entry/16-wayになっているようだ。





グラフ113〜118がI-TLB Sizeの結果である。こちらもNear Jump/Far Jumpでテストが分かれている。まずNear(グラフ113〜115)で見ると、Alder LakeはL1-I TLBが256Entryまで増強されており、その先は共有L2 TLBを利用、という構成になっている様に見える。またZen 2→Zen 3ではL1 I-TLBのLatencyそのものが大幅に下げられ、しかもUnifiedをやめたためかL2でもLatencyがそれほど増えないという恐ろしく素性の良い特性になっている。L1が多い分256segmentあたりまではAlder Lakeが優勢だが、その先はZen 3が圧倒的に低いLatencyで、Zen 2から随分改善がなされたことが見て取れる。
この傾向はFar Jump(グラフ116〜118)でも同じであり、一応Alder LakeはIntel系では最も低いLatencyでI-TLBアクセスが可能になっているが、Zen 3は更にその上を行く結果になっている。











ついでAssociativity。こちらもNear JumpとFar Jumpで、16/32/64/128-wayについてForward/Backward/Randomとあるので合計24ものグラフになってしまっている。まずはNear Jumpの16-way(グラフ119〜121)。Intel系はいずれも8-way構成になっているようで、9segment以降でLatency急増なのに対し、Fully AssociativityのZen 2/3は低め安定である。しかもZen 3はZen 2に比べてかなりLatencyを下げており(1.5cycle程度:Zen 2が4cycle強)、Fully Associativityの欠点である「Set AssociativityよりLatencyが増える」が事実上カバーしきれているのは素晴らしい事だと思う。この傾向は32-way(グラフ122〜124)
や64-way(グラフ125〜127)も同じである。強いて言えばAlder LakeはComet Lake/Rocket Lakeに比べて16segmentあたりまでのLatencyは急増ではなく次第に増えてゆく感じになっているあたりに色々工夫の跡は見られるが、本質的にはあまり変わらない。128-way(グラフ128〜130)ではZen 2は完全に破綻するが、Zen 3は恐ろしく低め安定を保っているのも、Unified TLBを辞めた効用だろうか?











グラフ131〜142はFar Jumpの場合であるが、傾向はNear Jumpの場合とほぼ同じだったので解説は割愛する。
とりあえずこのRMMAの分析結果を簡単にまとめると
Alder LakeはDecodeが6命令/cycleと言っているが、これがフルに使える状況は必ずしも多くなく、実質5命令/cycleの構成と考えた方が良い
Alder Lakeの内部はRocket Lake(=Cypress Cove≒Sunny Cove)から細かくファインチューニングがされている様に思えるが、ただSunny CoveがDecode 4命令/cycleのコアとしてはまだ最適化が十分ではなく、しかしながらAlder Lake(=Golden Cove)はその最適化を進めるのではなく、Decodeを6命令/Cycleに増やす方に舵を切った。つまりまだ内部の最適化は十分とは言えない。実際、あちこちミスマッチの部分が見受けられる。
--- Intelの説明によれば、Sunny CoveとGolden Coveの間に挟まったWillow Cove、以前の話では「キャッシュ周りの再設計」という話になっていた。乱暴な言い方になるが、今回Alder Lakeで高速化されたキャッシュ周りはTiger Lake(というか、Willow Cove)の世代で実装されたもので、このWillow Coveに6命令/cycleのDecoderを搭載したのがGolden Cove、というのが正確なところかもしれない。
なので、まだGolden Coveには最適化の余地がたっぷりあることになる。多分であるが、この辺りがもう少し熟成されるのは次(なのか、次の次なのかは微妙だが)のMeteor Lakeか、あるいは以前のロードマップには出てきていないが、一時期Alder Lakeの次の製品として名前の挙がっていたRaptor Lakeあたりに期待というあたりだろうか。
なぜRaptor Lakeが出てくるかというと、先のロードマップでMeteor LakeはIntel 4を利用するとされており、ところがIntel 4は2023年前半に量産開始とされるからで、仮に1月から量産をスタートしたとしても製品が出てくるのは2023年4月か5月である。つまりAlder Lakeで1年半持たせるのか? という話になるが、流石にこれは厳しい気がする。Raptor Lakeは実は断片的にそのコード名が出ていて、Intel 7(というか、Enhanced SuperFin)を利用するという話であった。Raptor Lakeが単にAlder Lake Refreshになるのか、それとも内部のEnhancementがあるのかは判らないが、とりあえずもう少しDecodeの実効処理命令を増やすとか、内部の高速化を図るとか、色々やれることは多そうだ。 ---
Zen 3はDecodeが4命令/CycleのCPUとしてはかなり完成された構成になっていると思える。この先のZen 4は、恐らく5命令/CycleのDecoderの実装になるだろう。それと懸案になっているAVX512の実装もこの世代で行われるかと思う。もっともこれはEPYC向けのニーズであって、仮に実装されたとしてもDesktop向けに有効化するかどうかはまた別の話であるが。
といったあたりかと思う。
●消費電力測定 / まとめと考察
○◆消費電力測定(グラフ143〜146)
絶対的な消費電力そのものは以前お届けしているが、Intelの14nm++とIntel 7を比較して、どの程度プロセス技術が改善されたのか、をちょっと確認してみたいと思う。
具体的にはBIOS Setup及びIntel Extreme Tuning Utilityを併用して、動作周波数を変化させながら、その際の消費電力を測定するというものだ。CPUの負荷はAIDA64のSystem Stability Testを利用し、CPU/FPU/cache/system Memoryに負荷をかけ続け、その際の平均消費電力を測定するという方法で行っている。
まず14nm++の代表例として、Core i9-11900Kの結果がグラフ143である。Intel Extreme Tuning Utilityでは最小が35倍だったため、35倍(3.5GHz)〜47倍(4.7GHz)まで実施した。47倍まで、というのはその47倍(Photo05)でThermal Throttlingが発生した(Photo06)。


同様にCore i9-12900Kの結果がこちら(グラフ144)。こちらは49倍(Photo07)で限界に達した(Photo08)。なおIntel Extreme Tuning Utilityで設定できる下限は32倍だったので、8倍〜31倍の動作設定はBIOS Setupで行っている。またE-Coreを連動させると倍率が39倍以上にならないので、今回はBIOS SetupでE-Coreを無効化し、P-Coreのみで比較した。


このグラフ143と144の、開始後30秒〜150秒の間の平均消費電力を、動作周波数との関係でプロットしたのがグラフ145である。破線は近似曲線であり、赤丸が付いている部分がThermal Throttlingが発生した箇所である。今回の場合、2つのマザーボードは異なるし、メモリも異なるから、0倍の時の消費電力が50Wほど異なるのは、プロセスの違いというよりはマザーボードとかメモリの違いに関係するものと考えた方が良い(Core i9-11900Kは比較的シンプルなASUS TUF GAMING Z590-PLUS WIFI、一方Core i9-12900Kはフル装備のASUS ROG MAXIMUS Z690 HEROである)。
そこで2つのグラフの初期値を一緒にするようにずらしたのがグラフ146となる。こうしてみると、確かに消費電力そのものは14nm++→Intel 7で大幅に減っていることが判る。実際47倍における消費電力差はIntel 14nm++が289W、Intel 7では163.5Wとなり、125.5Wもの消費電力削減につながっている。しかしながら、特に45倍あたりからIntel 7の消費電力の増え方が急激になっているのも事実で、近似曲線を見る限り50〜51倍あたりで両方のグラフがクロスしそうである。その意味では、「Intel 7になって消費電力削減が可能になった」のも「同じ消費電力ならより高速に動作する」のも事実だが、動作周波数の限界そのものはIntel 7の方がむしろ低いというか、先に破綻しそうだ。
全コア常時5GHz駆動を行ったCore i9-9900KSみたいな製品をIntel 7で作るのはかなり困難な様に思える。以前のレビューの際に「できれば100W位に消費電力を絞って使う方が幸せになれそうな気がする。」と書いたが、実際45倍あたりまでで止めておくのが幸せそうで、それ以上は急速に消費電力が増える事になると考えた方が良いだろう。
○考察
ということで大分遅くなったがAlder Lake Deep Diveを、Zen 3やRocket Lakeも併せてお届けした。もう既に入手されているユーザーも多いと思うし、レビューも色々出ているわけで、今更という感じかもしれないが。
Alder Lakeに対しての筆者の感想は、RMMAのところの結論でも述べたように「まだ熟成の余地がある」に尽きる。もっと言えば、Cypress Cove(≒Sunny Cove)の中身が、思ったよりはSkylakeに近かった事で、基本CoveシリーズはSkylakeの延長にある事が確認された格好だ。Alder Lakeは高い性能を叩き出しているが、それはDecoderとALUを増量するという力業が成せる技であって、それで増えそうな消費電力をプロセスの微細化で抑え込んだという、やや荒っぽいコアである。これがもう少し洗練されるのは、Raptor LakeかMeteor Lakeの世代になりそうだ(そのMeteor Lakeはちょっととんでもない話を聞いたが、裏が取れていないので今回は割愛する)。まぁ荒っぽくても性能は出る訳で、ややピーキーな部分が無くもないが、Intel 7がちゃんと想定通りの性能が出たことで救われた感がある。
一方Zen 3はそろそろこれをいじるのも限界、という感じが改めて確認できた。3D V-Cacheの搭載でメモリアクセスを多用するアプリケーションでは性能が向上しそうだが、その効果は限定的にならざるを得ない。ただここまで成熟している以上、次は5命令/cycleのDecoderの搭載はほぼ決定的だと筆者は考えている。5nmプロセスに移行すれば利用できるトランジスタ数も配線も増えるから、AVX512をサポートしても、それに対応帯域をL1 D-CacheやL2 Cacheに与えるのはそれほど難しくないだろうし、AVX512ユニットの実装もそれほどエリアペナルティ無しに実現できるだろう。はっきりしないのが、IntelのGNAにあたるNeural Processorの搭載の有無である。現状IntelのGNAがごく限られたアプリケーションしか対応していないことを考えると、多分Zen 4の世代には入らない(か、そうしたものはZen 4の世代には統合されるとみられるNavi 2ベースのGPUにオフロードする)のではないかと思う。