
Metaが大規模言語モデル「LLaMA」を発表、GPT-3に匹敵する性能ながら単体のGPUでも動作可能



MetaのAI研究組織であるMeta AI Researchが、大規模言語モデル「LLaMA(Large Language Model Meta AI)」を2023年2月24日に発表しました。Meta AI Researchによれば、LLaMAはOpenAIのGPT-3よりもパラメーター数がずっと小さく、単体GPUでも動作可能でありながら、ベンチマークテストの一部ではGPT-3を上回ったとのことです。
https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Meta unveils a new large language model that can run on a single GPU [Updated] | Ars Technica
https://arstechnica.com/information-technology/2023/02/chatgpt-on-your-pc-meta-unveils-new-ai-model-that-can-run-on-a-single-gpu/
LLaMAのパラメーター数は70億から650億で、WikipediaやCommon Crawl、C4など、一般に公開されているデータセットで学習しているとのこと。Meta AI Researchの研究員であるGuillaume Lample氏は「GPT-3やDeepMindのChinchilla、GoogleのPaLMと異なり、LLaMAは公開されているデータセットのみを使用し、オープンソースと互換性がある再現可能な作業を行います。既存のモデルのほとんどは公開されていないか文書化されていないデータを使って学習しています」と述べています。
Unlike Chinchilla, PaLM, or GPT-3, we only use datasets publicly available, making our work compatible with open-sourcing and reproducible, while most existing models rely on data which is either not publicly available or undocumented.
2/n pic.twitter.com/BNz9oHqblZ— Guillaume Lample (@GuillaumeLample) February 24, 2023
また、Meta AI Researchによると、パラメーター数130億のLLaMA-13Bを単体GPUで実行し、BoolQ・PIQA・SIQA・HellaSwag・WinoGrande・ARC・OpenBookQAという8つのベンチマークで「常識的推論」を測定したところ、一部のテーマではパラメーター数1750億のGPT-3を上回る性能を示したとのこと。
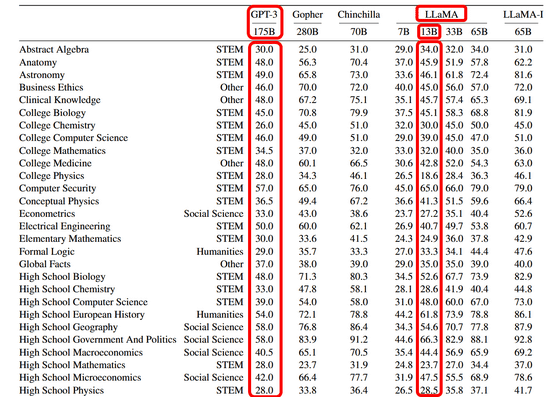
パラメーター数とは、機械学習モデルが入力データに基づいて予測や分類を行うために使用する変数(パラメーター)の量のことで、モデルの性能を左右する重要な要素です。パラメーター数が大きければ大きいほどより複雑なタスクを処理して安定した出力を生成できますが、パラメーター数が大きくなるとモデル自体のサイズも大きくなり、同時に求められるコンピューター資源も多くなります。
「GPT-3よりも圧倒的に少ないパラメーター数でGPT-3と同等の性能を示した」というLLaMA-13Bは、GPT-3よりもコストパフォーマンスが優れているといえます。また、GPT-3はAIに最適化したアクセラレーターを複数台使わなければ動作しないのに対し、LLaMA-13Bは単体GPUでも問題なく動作したことから、コンシューマーレベルのハードウェア環境でもChatGPTのようなAIを動かせる可能性があります。
Meta AI ResearchはLLaMAを「基本モデル」とみなしており、今後このLLaMAがMetaの自然言語処理モデルの基盤となり、「質問応答、自然言語の理解あるいは読解、現在の言語モデルの能力と限界の理解」などの自然言語の研究に役立ち、アプリケーションを潜在的に強化することに期待しています。
なお、記事作成時点でLLaMAの一般公開は予定されていませんが、LLaMAによる簡易的な推論モデルの一部がGitHubで公開されており、完全なコードとニューラルネットワークで学習した重みは、Googleフォームを通じてMeta AI Researchに連絡すればダウンロードが可能とのことです。
GitHub - facebookresearch/llama: Inference code for LLaMA models
https://github.com/facebookresearch/llama





